
Graph DB : Comment modéliser mes données ?
Cet article fait partie d’une série sur les bases de données orientées graphe, dont vous retrouverez l’intégralité des articles ici : Les bases de données orientées graphe
Autant vous prévenir, cet article est costaud !
Il dépasse largement les 30 minutes de temps de lecture. Donc, prenez votre temps pour le lire, et lisez-le en plusieurs fois si nécessaire.
Bonne lecture à tous
Comment modéliser correctement mes données dans un graphe ?
Contrairement à une base de données SQL, où la relation n’est qu’une contrainte permettant d’assurer une correspondance entre les valeurs des lignes de 2 différentes tables, dans une Graph DB, les relations sont des citoyens de première classe !
Ces dernières assurent non seulement la liaison entre 2 entités, mais en plus, elles l’enrichissent à travers des propriétés personnalisées, et lui donnent du sens.
Dès lors, une question légitime que l’on se pose est :
Comment être sûr que ma modélisation est correcte pour une base de données orientée graphes ?
Un travail d’équipe
La modélisation des données dans un graphe est avant tout, un travail d’équipe !
Il s’agit d’un effort collaboratif où le domaine d’application est analysé par les parties prenantes du projet (aka stakeholder) et les développeurs, afin de trouver le modèle optimal à utiliser. Il est important que les parties prenantes comprennent le domaine métier, et soient prêtes à poser des questions détaillées sur le fonctionnement de l’entreprise ou du système en cours d’étude.
NDLR : Les parties prenantes citées ici sont les Business Analysts, les architectes, les managers et les chefs de projet
Un processus simple et efficace
Pour faciliter et orchestrer aisément ce travail d’équipe, il existe un processus à suivre permettant :
- De modéliser correctement ses données
- Faciliter les itérations du modèle de données.
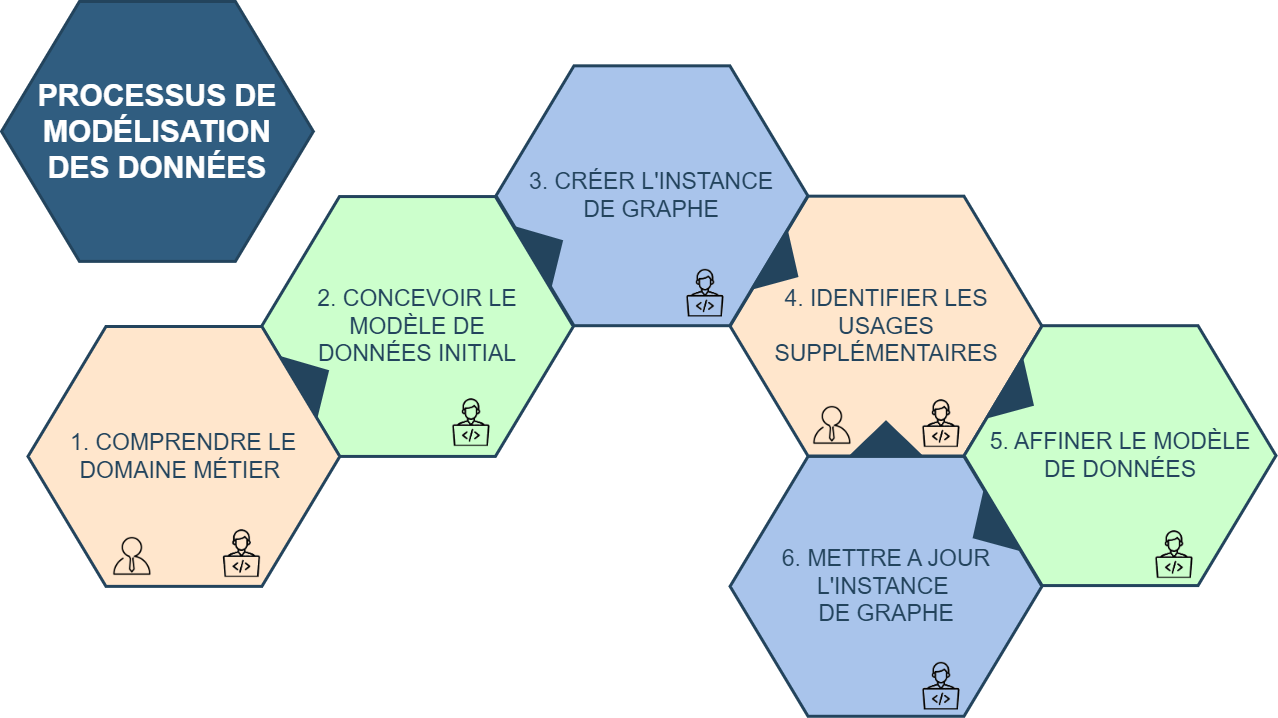
Il s’agit d’un processus itératif qui fait bien la distinction entre :
- Le modèle de données : sur lequel on pose nos réflexions, et où on définit le format des données à traiter
- L’instance du graphe de données : qui est une instance du graphe dans une base de données, remplie avec de vraies données, et dont la structure correspond à celle du modèle de données.
Modèle versus Instance
La différence entre modèle et instance peut sembler floue au premier abord, pourtant elle est assez simple et sa visualisation est assez distinctive.
Prenons le cas d’une représentation de consommation d’API par des applications SPA, à travers l’exemple suivant :

On y voit :
- 2 types de nœuds :
Application SPAetAPI REST.
Chacun avec les propriétés :idde type int ou guid,nomde type stringurlde type uri
- 1 type de relation :
CONSOMME.
Avec les propriétés :protocole, une énumération des protocoles possiblesrate-limit-count, le nombre d’appels possible avant de dépasser la limite d’appels par périoderate-limit-period, la période de cumule de la limitation des appelsauthentification, une énumération des types d’authentification supportées
Sur ce schéma, aucune valorisation n’est présente. On comprend qu’une Application SPA peut consommer une API Rest, qu’elles ont des propriétés qui permettent de les identifier, mais on ne sait pas quelle application consomme quelle API.
C’est là qu’intervient l’instance de graphe :
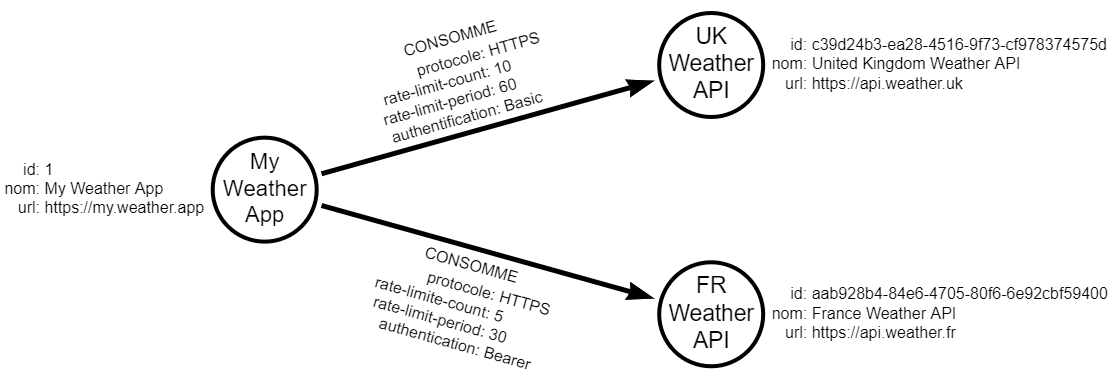
On y distingue très clairement l’application My Weather App qui consomme les APIs UK Weather API et FR Weather API, avec des valeurs de relations qui diffèrent d’une API à l’autre.
Modèle de graphe != Modèle relationnel
Avant de passer à la mise en pratique du processus, revenons sur le travail d’équipe et l’importance de comprendre le domaine métier.
Pourquoi est-il si important que les parties prenantes comprennent pleinement le domaine métier ?
Et bien parce que l’approche utilisée pour construire un modèle de graphe est différente de celle d’un modèle relationnel.
Pour une base de données relationnelle, généralement on commence par :
- Créer le schéma de données SQL :
- On crée des tables SQL correspondant aux entités du domaine
- On ajoute les colonnes dans les tables, colonnes qui correspondent aux propriétés des entités citées précédemment
- Puis on établit les jointures entre nos différentes tables SQL
- Et, seulement ensuite, on va se poser les questions auxquelles on doit répondre, et déterminer comment on peut y répondre à travers notre modèle de données
En résumé :
Avec un modèle relationnel, on définit d’abord une structure de stockage des données, puis on détermine ensuite comment on peut répondre aux questions/besoins du domaine métier en utilisant notre modèle de données.
Pour un modèle de graphe, on fonctionne dans le sens inverse :
- On cherche d’abord les questions auxquelles on doit répondre
- Et ENSUITE on modélise notre graphe :
- En créant les nœuds correspondants aux entités du domaine,
- En établissent les relations entre nos différents nœuds, de manière à répondre aux questions/besoins du domaine métier,
- Puis en incluant des propriétés sur les nœuds et les relations
En résumé :
Avec un modèle de graphe, on cherche d’abord les questions auxquelles on doit répondre, puis on crée un modèle de données conçu pour répondre de manière simple et efficace à ces questions.
Et c’est parce que l’on doit connaître ces questions avant de concevoir le modèle de données que la compréhension du domaine métier et de ses besoins est une priorité.
Mise en pratique du processus
Pour mieux vous approprier l’approche citée précédemment, je vous propose une mise en situation à travers le cas d’usage qui suit.
Cas d’usage
Intéressons-nous à ZeeDash :
- ZeeDash est un outil (fictif) de gestion de tableau de bord à destination des entreprises.
- Le Product Manager de ZeeDash souhaite mettre en place un système de gestion des autorisations d’accès à la fois fiable et performant.
Contexte fonctionnel
Sur ZeeDash, n’importe qui peut s’inscrire en tant que nouvel Utilisateur et déclarer une Entreprise.
Ces Entreprises peuvent contenir soit des Divisions, permettant de représenter l’organisation hiérarchique d’une société, soit des Tableau De Bord, correspondant à un agrégat de liens vers d’autres sites et de graphiques de données.
Les Divisions peuvent soit contenir d’autres Divisions (avec une profondeur hiérarchique maximale de 4), soit des Tableaux de bord.
NDLR : Les sources des graphiques de données ne seront pas abordées dans cet article.
Pour qu’un utilisateur puisse consulter les Tableaux de bord d’une Entreprise ou d’une Division, il doit :
- Être membre de l’Entreprise
- Avoir un niveau d’accès suffisant (direct ou hérité) pour y accéder
Les utilisateurs peuvent avoir les rôles suivants, sur les Entreprises, les Divisions ou les Tableaux de bord :
| Rôle | Description |
|---|---|
| Lecteur | N’autorise que la consultation des Tableaux de bord |
| Contributeur | Reprend les droits du Lecteur, et peut en plus ajouter des Tableaux de bord sur les Entreprises/Divisions où le rôle lui est assigné |
| Propriétaire | Reprend les droits du Contributeur, peut affecter/révoquer des accès utilisateurs, ainsi que créer de nouvelles Divisions |
Les rôles autorisés sont hérités, c’est-à-dire qu’un utilisateur avec le rôle Propriétaire sur l’Entreprise, sera automatiquement Propriétaire sur toutes les Divisions et tous les Tableaux de bord associés à cette Entreprise.
Un Utilisateur est caractérisé par :
- son nom complet,
- son adresse email,
- son identifiant unique.
Une Entreprise est caractérisée par :
- son nom,
- son identifiant unique.
Une Division est caractérisée par :
- son nom,
- son identifiant unique.
Un Tableau De Bord est caractérisé par :
- son intitulé,
- son identifiant unique.
Problématique
ZeeDash souhaite valider que les autorisations d’un utilisateur sont suffisantes pour lui laisser le droit d’accéder à un élément.
Pour déterminer si l’accès est autorisé, ces 3 informations sont nécessaires :
- L’élément en cours d’accès : Le nom/intitulé de l’Entreprise, la Division ou le Tableau De Bord concerné
- L’utilisateur qui essaye d’y accéder : son nom complet
- Le niveau d’accès requis : le nom du rôle
NDLR : Dans un cas d’usage réel, l’usage des identifiants uniques aurait prévalu. J’ai sciemment choisi ces propriétés pour la facilité de lecture des éléments techniques à suivre.
Critère d’acceptation
Le cas d’usage sera considéré comme valide si le modèle de données permet de répondre aux questions suivantes :
- Puis-je valider qu’un utilisateur est membre d’une Entreprise ?
- Puis-je valider qu’un utilisateur a le bon rôle pour accéder à un élément ?
- Puis-je lister tous les utilisateurs, et leurs rôles respectifs, ayant accès à un élément donné ?
- Puis-je mettre à jour les droits d’un utilisateur et voir instantanément la différence de résultat de la requête précédente ?
I. Comprendre le domaine métier et ses cas d’usages
Comme évoqué précédemment, le processus de modélisation est un travail d’équipe.
Et en ce sens, une des premières choses à faire pour la compréhension du besoin est d’identifier les parties prenantes et les développeurs qui interviendront sur le projet 😅
Les parties prenantes auront alors la tâche d’amasser les plus d’informations possibles sur le système à réaliser, de trier toutes ces informations, pour en déduire le périmètre d’intervention fonctionnel ainsi que les cas d’usage de l’application finale que coderont les développeurs.
Lors de cette analyse, tous les acteurs du système (acteurs directs/indirects, humain ou non …) doivent être identifiés, dès l’instant où ils font partie des cas d’usages.
Les cas d’usage doivent ensuite être rédigés pour que les développeurs puissent facilement comprendre. Le format final de cette rédaction dépendra de votre méthodologie de travail (Scrum, Cycle en V, …), mais je vous conseille vivement de fournir au moins ces 3 éléments à vos équipes :
- le contexte fonctionnel
- le problème à résoudre
- les critères d’acceptations selon lesquels le problème sera considéré comme valide
Le résultat de cette analyse, et les éléments rédigés, sont alors présentés aux développeurs par les parties prenantes, avec lesquels ils s’accordent pour commencer le travail, ou affiner les spécifications si le niveau d’informations ne semble pas suffisant/clair.
II. Concevoir le modèle de données initial
Pour concevoir mon modèle de données initial, j’utilise le tableau de correspondance suivant afin d’extraire les informations d’une expression besoin, et savoir où les placer dans mon modèle de données :
| Élément de graphe | Élément à extraire |
|---|---|
NœudsVertices |
Les NOMS COMMUNS Cela peut correspondre à un objet, une typologie de personne … l’important c’est que ça référence un élément unitaire dans un usage. |
RelationsEdges |
Les VERBES et les ÉTATS DE POSSESSION Les verbes correspondent généralement à des actions effectuer par/sur/avec les “nœuds”, et les états de possession correspondent à des valorisations d’états d’un nœud par rapport à un autre. |
ÉtiquettesLabel |
Les étiquettes permettent de donner un “type fort” aux nœuds. Elles sont donc généralement valorisées sur les nœuds par les NOMS COMMUNS qui ont permis de trouver les nœuds. |
PropriétésProperties |
Toutes les informations auxiliaires que l’expression de besoin peut comporter, et qui ont de l’importance. |
À la recherche des nœuds
À partir du tableau précédent, en commençant par chercher les nœuds, on extrait les éléments suivants :
| Noms communs | Commentaire |
|---|---|
| Utilisateur | Les personnes qui s’enregistrent sur ZeeDash et qui souhaitent accéder à des éléments |
| Entreprise | Les unités organisationnelles de haut niveau représentent le point d’entrée d’une entreprise |
| Division | Filiales ou divisions d’une entreprise dans une Entreprise |
| Tableau De Bord | Tableaux de bord associés à une Entreprise ou une Division |
Attention : Il serait tentant d’utiliser les noms communs suivants comme nœuds, mais je vous le déconseille :
| Noms communs | Commentaire |
|---|---|
| Élément | Il s’agit d’un nom générique, qui peut correspondre soit à une Entreprise, soit à une Division, soit à un Tableau De Bord. Il est déconseillé d’utiliser des éléments génériques dans un graphe. Les nœuds des graphes sont censés calquer la réalité. |
| Rôle | Selon la description, un rôle est un ensemble de droits autorisant un utilisateur à effectuer diverses actions sur les éléments qui composent le graphe. Pour autant, dans la description, les rôles sont tous énumérés, et la possibilité de modifier le rôle d’un utilisateur est clairement décrite. Ils correspondent donc à un état de possession, plus qu’à une entité à part entière, et seront portés par une relation. |
En définitive nous obtenons les types de nœuds suivants pour notre modèle de graphe :

Chaque nœud contient :
- Une étiquette correspondant au nom commun qui le décrit
- Un ensemble de propriétés correspondant aux éléments décrits dans la description du cas d’usage.
La mise en relation
Occupons-nous désormais des relations qui lient toutes ces entités.
À partir du tableau présenté en début de chapitre, il est possible d’extraire les éléments suivants :
| Nœud racine | Relation | Nœud cible | Commentaire |
|---|---|---|---|
| Utilisateur | EST_MEMBRE_DE | Entreprise | Indique que l’utilisateur est membre de l’Entreprise et peut accéder à ses éléments. |
| Entreprise | CONTIENT | Division ou Tableau De Bord |
Indique les éléments de niveau “inférieur” contenu dans l’Entreprise. |
| Division | CONTIENT | Division ou Tableau De Bord |
Indique les éléments de niveau “inférieur” contenu dans la Division. |
| Utilisateur | A_LE_ROLE | Entreprise ou Division ou Tableau De Bord |
Indique le rôle qu’un utilisateur a sur un élément, et ses descendants. Le nom du rôle est porté par une propriété de la relation. |
Et après recherche des relations, nous obtenons cette cartographie des relations (les propriétés des nœuds ont été masquées pour plus de lisibilité) :
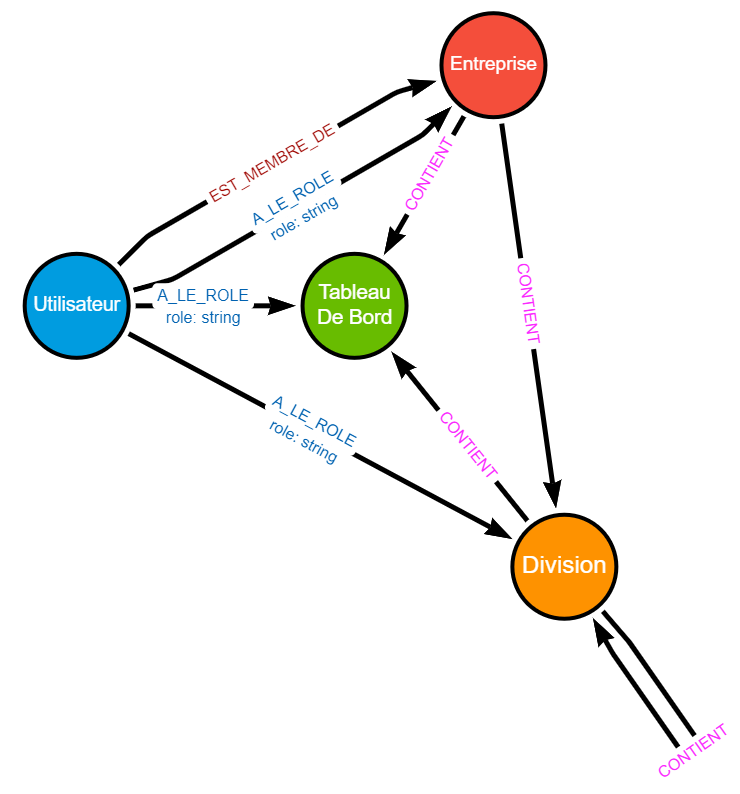
Et voilà ! Notre modèle de données initial est terminé 🎉
Mais avant de passer à l’étape suivante, je me dois de vous donner quelques informations supplémentaires sur les “bonnes pratiques” de modélisation.
Conventions de modélisation
Un fait généralement admis dans la modélisation de données est que :
Les relations intentionnées sont plus utiles que les relations génériques. Elles assurent un filtrage plus explicite et apportent de meilleures performances.
Dans notre cas d’usage, les relations associées aux rôles sont génériques et font appel à une propriété pour définir le rôle de l’utilisateur sur l’élément.
En suivant la recommandation précédente, notre modélisation aurait pu être définie comme suit :
| Nœud racine | Relation | Nœud cible | Commentaire |
|---|---|---|---|
| Utilisateur | EST_PROPRIETAIRE_DE | Entreprise ou Division ou Tableau De Bord |
Indique que l’utilisateur est un des propriétaires de l’élément. |
| Utilisateur | EST_CONTRIBUTEUR_DE | Entreprise ou Division ou Tableau De Bord |
Indique que l’utilisateur est un des contributeur de l’élément. |
| Utilisateur | EST_LECTEUR_DE | Entreprise ou Division ou Tableau De Bord |
Indique que l’utilisateur est un des lecteur de l’élément. |
Note : Dans le cadre de cet article, j’ai intentionnellement simplifié la représentation des relations du modèle.
Conventions d’écriture
Les règles d’écriture pour un graphe de données sont assez peu nombreuses, mais elles assurent une lecture équivalente à toutes les personnes qui consultent un graphe.
| Élément | Attribut | Commentaire |
|---|---|---|
NœudsVertices |
ÉtiquettesLabel |
En Upper CamelCase : Avec une majuscule à chaque mot qui compose le nom Par exemple : TableauDeBord, TrainDeNuit, … |
NœudsVertices |
PropriétésProperties |
En Lower CamelCase : Avec une majuscule à chaque mot qui compose le nom, excepté le premier mot Par exemple : nomComplet, role, … |
RelationsEdges |
Type | En Screaming Snake Case : Tout en majuscule, avec des soulignés (underscore) à la place des espaces Par exemple : EST_PROPRIETAIRE_DE, CONTIENT, … |
RelationsEdges |
PropriétésProperties |
En Lower CamelCase : Avec une majuscule à chaque mot qui compose le nom, excepté le premier Par exemple : nomComplet, role, … |
Notre modèle de données est-il valide ?
Revenons à notre modèle de données.
Afin de valider sa conception, il est primordial de nous assurer qu’il répond correctement aux critères d’acceptation qui ont été émis.
Pour cela, reprenons les questions dans l’ordre, et validons le modèle :
- Puis-je valider qu’un utilisateur est membre d’une Entreprise ?
Oui, à travers la relationEST_MEMBRE_DEqui lie un Utilisateur à une Entreprise.

- Puis-je valider qu’un utilisateur a le bon rôle pour accéder à un élément ?
Oui, à travers la relationA_LE_ROLEqui définit le rôle qu’un Utilisateur a sur une Entreprise, une Division ou un Tableau De Bord.
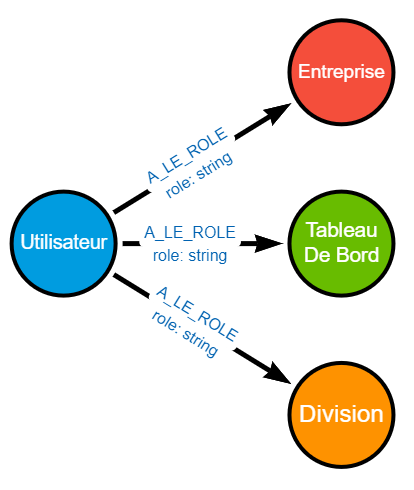
- Puis-je lister tous les utilisateurs, et leurs rôles respectifs, ayant accès à un élément donné ?
Oui, à travers :- La relation
A_LE_ROLEqui défini le rôle d’un Utilisateur sur un des éléments - La relation
CONTIENTqui permet de remonter sur les éléments ancestraux afin de déterminer quels utilisateurs a un rôle sur un des éléments parents.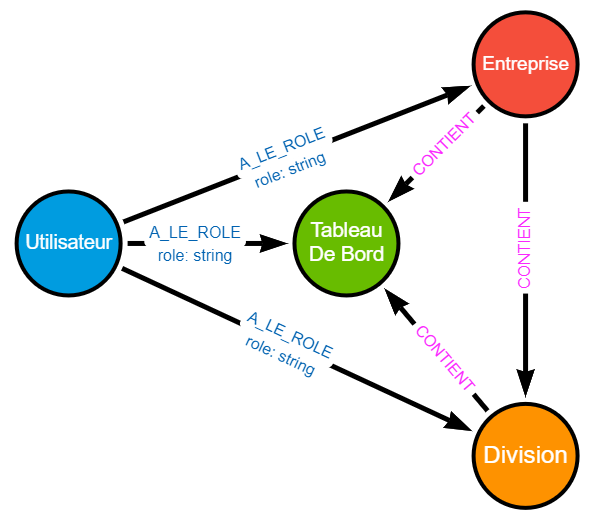
- La relation
- Puis-je mettre à jour les droits d’un utilisateur et voir instantanément la différence de résultat de la requête précédente ?
Oui, à mettant à jour la propriétérolede la relationA_LE_ROLE, il est possible instantanément de redéfinir le rôle qu’un Utilisateur a sur une Entreprise, une Division ou un Tableau De Bord.
Notre modèle de données valide donc les critères d’acceptations du besoin exprimé.
III. Créer l’instance de graphe avec des données
Notre modèle de données étant prêt, il faut désormais créer une première version du graphe de données. Pour le besoin de cet article, je vais utiliser ma situation professionnelle (au moment de la rédaction de l’article).
Je vais faire au plus simple, il y aura :
- 1 Entreprise : C2S.
- 1 Division : Dev & IA
- 1 Tableau De Bord : OnBoarding
- 3 utilisateurs :
Pour l’affectation des rôles :
- Je serai ‘Propriétaire’ de C2S
- Matthieu sera ‘Contributeur’ de la Division ‘Dev & IA’
- Baptiste sera ‘Lecteur’ sur le Tableau De Bord ‘OnBoarding’
Pour aider à la validation du graphe, un quatrième utilisateur, fictif, sera ajouté : Norbert LE VIKING.
Il ne sera pas membre de C2S, et ne disposera d’aucun rôle sur les éléments cités précédemment.
Cette description doit nous donner un graphe ayant cette forme :
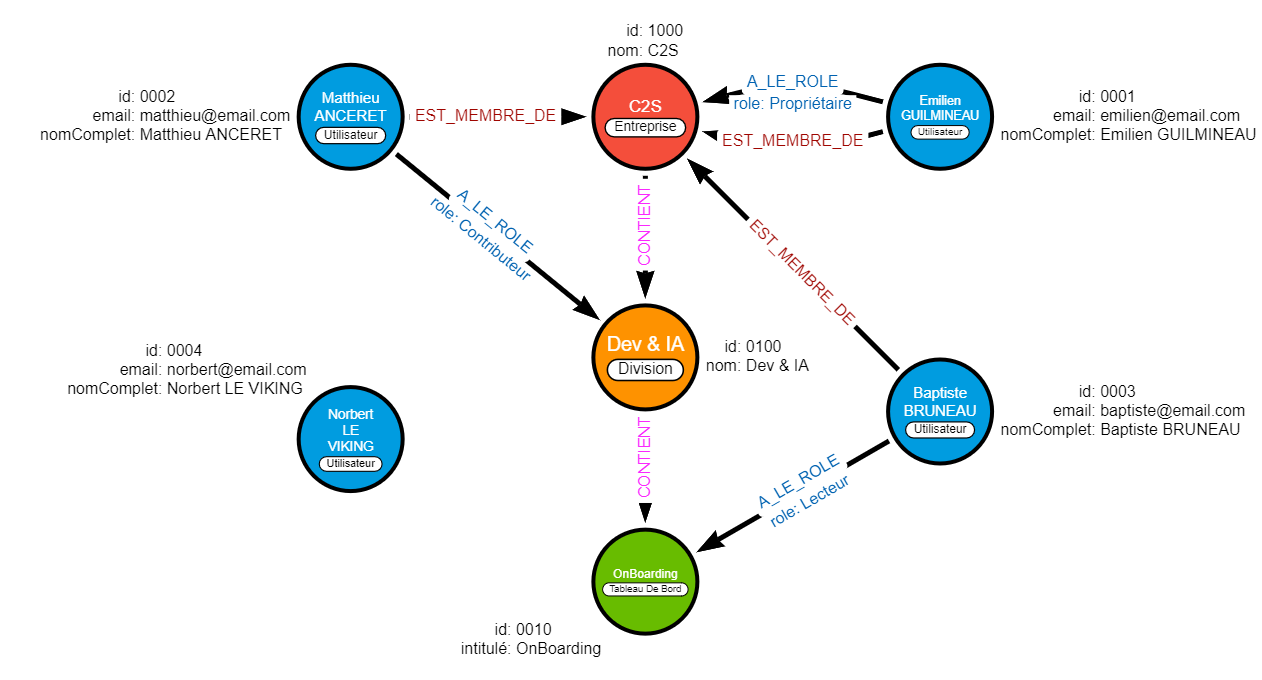
La création des données
Nous pouvons alors rédiger un premier script Cypher permettant d’insérer les données en base de données :
|
|
Note : Nous “étudierons” le langage Cypher dans un article à venir. Votre compréhension de ce script n’est pas primordiale pour la compréhension du reste de l’article.
On obtient alors un graphe prêt à être utilisé, tel que celui-ci, après insertion dans une base de données RedisGraph :
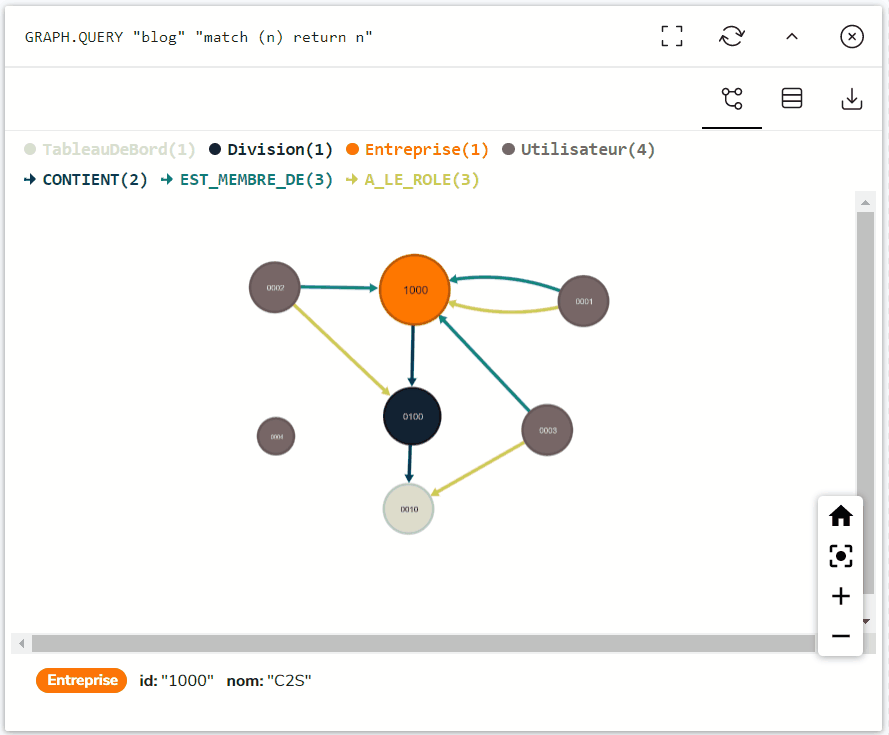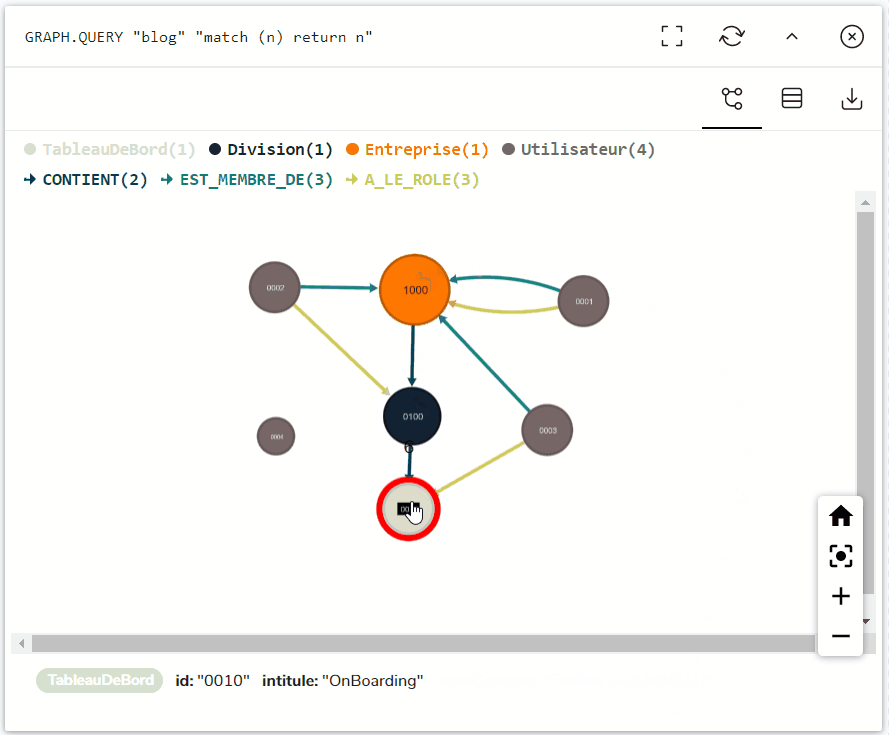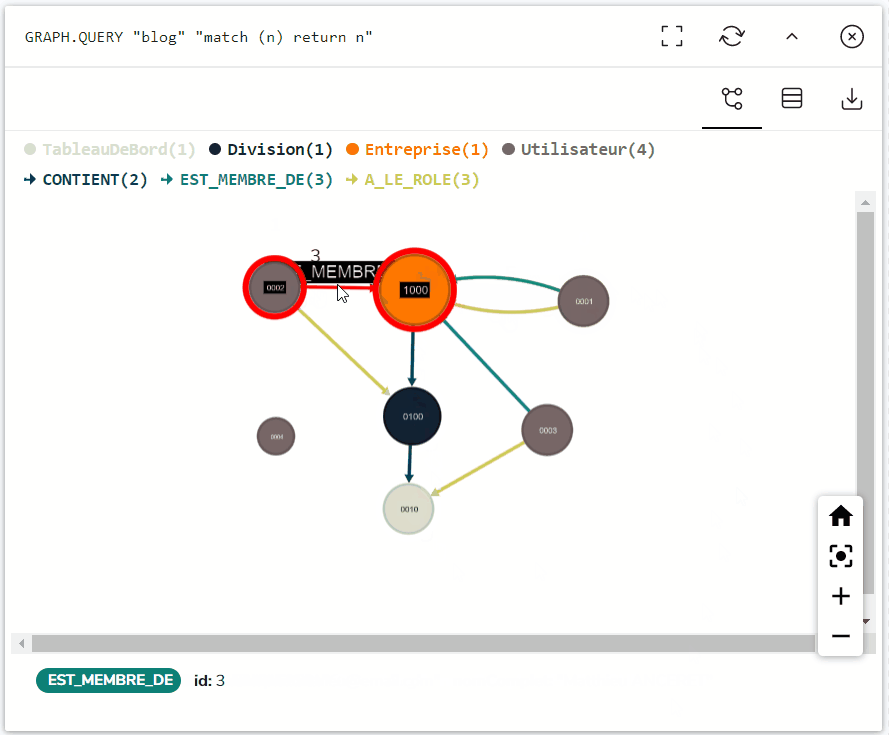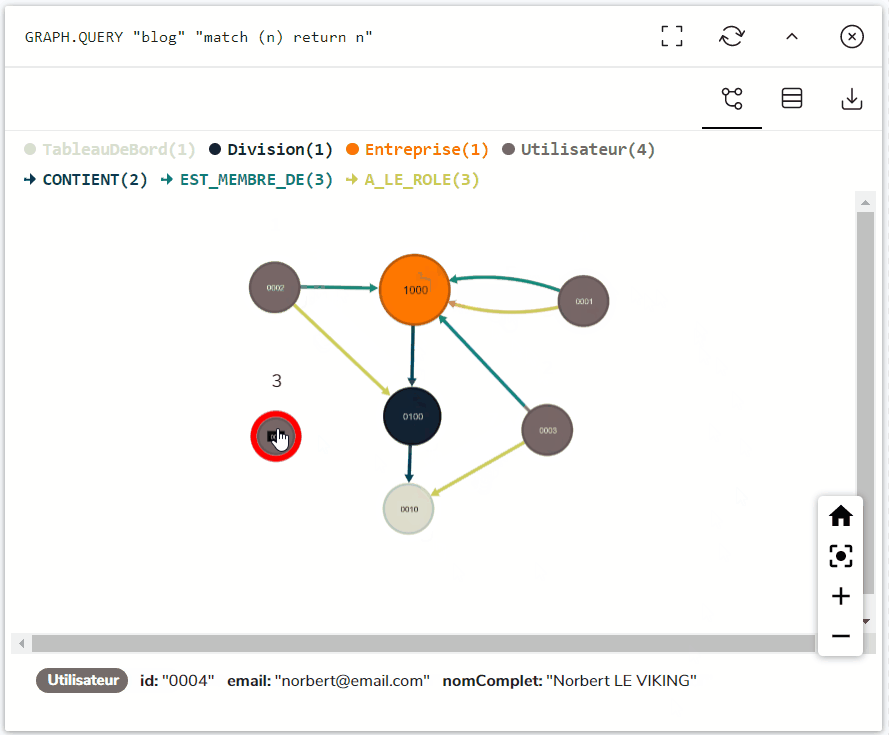
La validation du graphe
Afin de valider son contenu, nous devons réaliser quelques requêtes Cypher. Reprenons les questions des critères d’acceptation.
Rappel : Nous “étudierons” le langage Cypher dans un article à venir. Votre niveau de connaissance de ce langage n’est pas primordial pour la compréhension du reste de l’article.
1. Puis-je valider qu’un utilisateur est membre d’une Entreprise ?
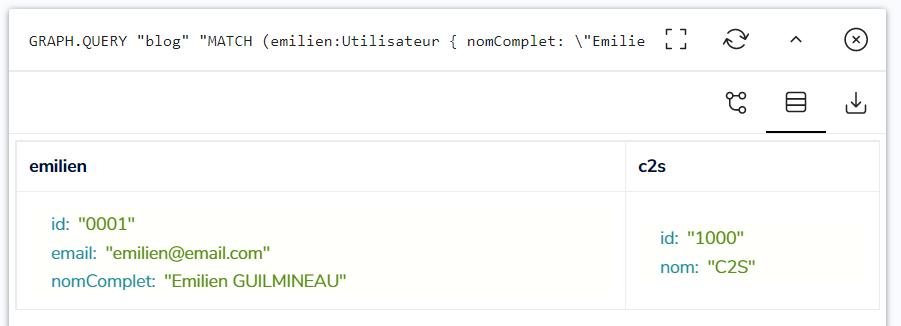
Pour valider que notre graphe permet de répondre à la question de l’appartenance d’un membre, il nous faut un requête Cypher permettant de sélectionner l’Utilisateur et l’Entreprise, puis de valider qu’une relation de type EST_MEMBRE_DE les unis.
Si la requête suivante retourne les nœuds pour Emilien et C2S, c’est que la relation entre Emilien à C2S existe :
|
|
Les 2 nœuds sont retournés par RedisGraph, la relation entre les 2 éléments est validée :
Mais pour valider que cette requête est correcte, nous devons l’exécuter sur un cas invalide, où la relation n’existe pas.
Essayons de trouver cette même relation entre Norbert et C2S :
|
|
Aucun nœud n’est retourné par RedisGraph, seulement les statistiques d’exécution de la requête. Ce qui indique que la relation entre les 2 éléments n’existe pas :
Cette requête Cypher, valorisée avec Emilien puis Norbert, nous a permis de confirmer que notre modèle de graphe valide la première question des critères d’acceptation.
2. Puis-je valider qu’un utilisateur a le bon rôle pour accéder à un élément ?
Pour valider que notre graphe permet de répondre à la question du rôle d’un Utilisateur sur un élément, il nous faut une requête Cypher permettant de sélectionner l’Utilisateur et l’élément, et de valider que la propriété role de la relation a la bonne valorisation.
Si la requête suivante retourne les nœuds pour Baptiste et OnBoarding, ainsi que la relation A_LE_ROLE, c’est qu’il a le rôle souhaité sur l’élément ciblé :
|
|
Les 2 nœuds et la relation sont retournés par RedisGraph, l’attribution du rôle est validée :
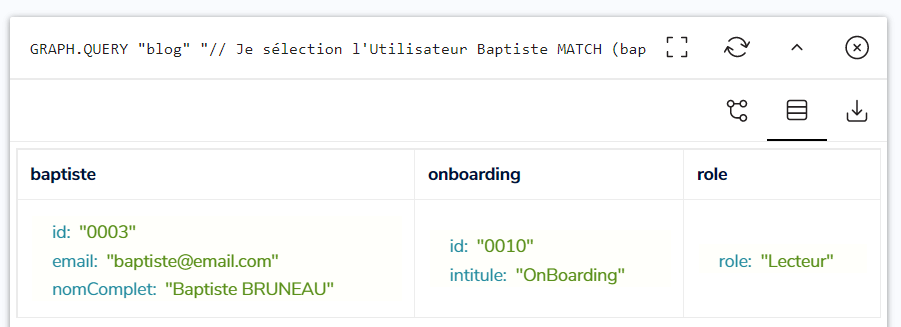
Mais pour valider que cette requête est correcte, nous devons l’exécuter sur un cas invalide, où l’utilisateur ne dispose pas du rôle ciblé.
Essayons de trouver cette même relation entre Baptiste et la Division ‘Dev & IA’ :
|
|
Aucun nœud n’est retourné par RedisGraph, seulement les statistiques d’exécution de la requête. Ce qui indique que la relation entre les 2 éléments n’existe pas, et donc que le rôle ne lui est pas affecté sur cet élément :
Cette requête Cypher, ciblant d’abord le Tableau De Bord ‘OnBoarding’, puis la Division ‘Dev & IA’, nous a permis de confirmer que notre modèle de graphe valide la deuxième question des critères d’acceptation.
3. Puis-je lister tous les utilisateurs, et leurs rôles respectifs, ayant accès à un élément donné ?
Pour valider que notre graphe permet de lister tous les utilisateurs et leur rôle, ayant accès un élément donné, il nous faut un requête Cypher permettant :
- de sélectionner l’Utilisateur
- de sélectionner l’élément source dans la hiérarchie,
- de parcourir la hiérarchie des éléments à travers la relation
CONTIENT
On obtient alors une requête Cypher correspondant à ceci :
|
|
Les 3 nœuds des utilisateurs sont retournés par RedisGraph, ainsi que les rôles associés :
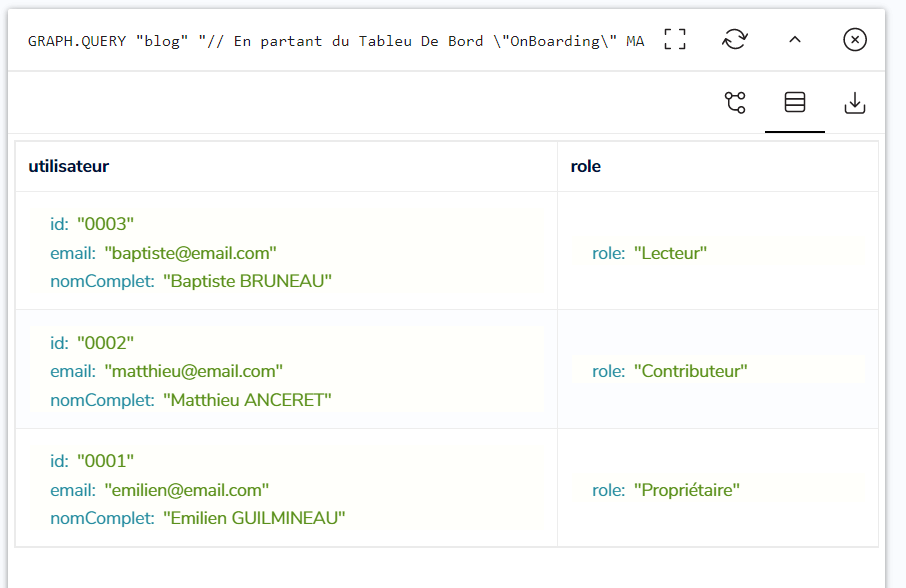
Cet exemple montre qu’en partant de l’élément le plus bas dans la hiérarchie, un Tableau De Bord, on récupère tous les utilisateurs ayant un rôle sur les éléments parents, et confirme donc que la recherche ascendante fonctionne.
Par ailleurs, le résultat de la requête ne contient pas Norbert LE VIKING. Donc les utilisateurs n’ayant pas de rôles sur la hiérarchie d’éléments sont bien écartés.
Mais pour valider que cette requête est correcte nous devons l’exécuter sur un niveau hiérarchique supérieur (ici, la Division ‘Dev & IA’), afin de s’assurer de ne pas retourner des utilisateurs non autorisés.
Recommençons donc, en partant la Division ‘Dev & IA’ :
|
|
Seuls les nœuds de Matthieu et Emilien sont retournés par RedisGraph. Ce qui indique que Baptiste n’est pas concerné par la Division ‘Dev & IA’, et n’y a pas accès :
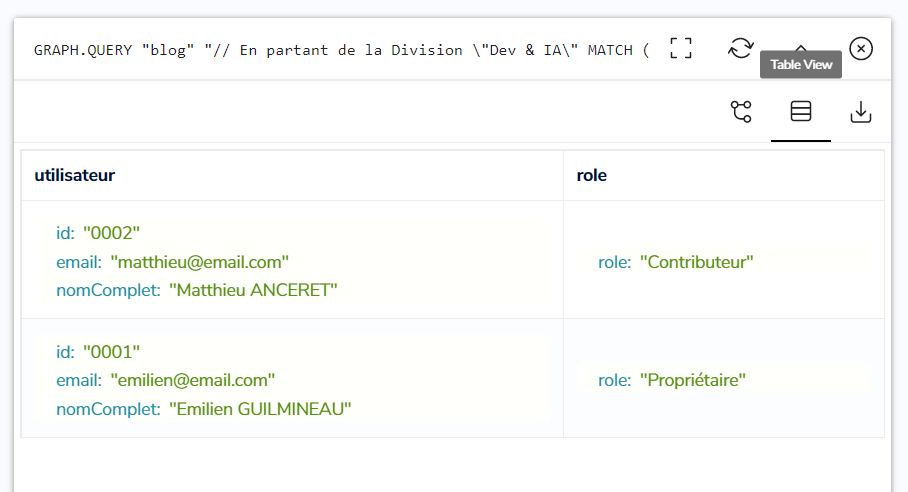
Cette requête Cypher, ciblant d’abord le Tableau De Bord ‘OnBoarding’, puis la Division ‘Dev & IA’, nous a permis de confirmer que notre modèle de graphe valide la troisième question des critères d’acceptation.
4. Puis-je mettre à jour les droits d’un utilisateur et voir instantanément la différence de résultat de la requête précédente ?
Pour valider la prise en compte immédiate des modifications de rôles, un trio de requête Cypher suffit :
- Je recherche les rôles d’Utilisateur sur un élément, un Tableau De Bord par exemple
- Je modifie le rôle d’un Utilisateur sur l’élément ciblé
- Je recherche à nouveau les rôles d’Utilisateur sur le Tableau De Bord, et je compare les résultats
On repart donc de la requête du sous-chapitre précédent :
|
|
Qui nous retourne les 3 nœuds des utilisateurs, ainsi que les rôles associés :
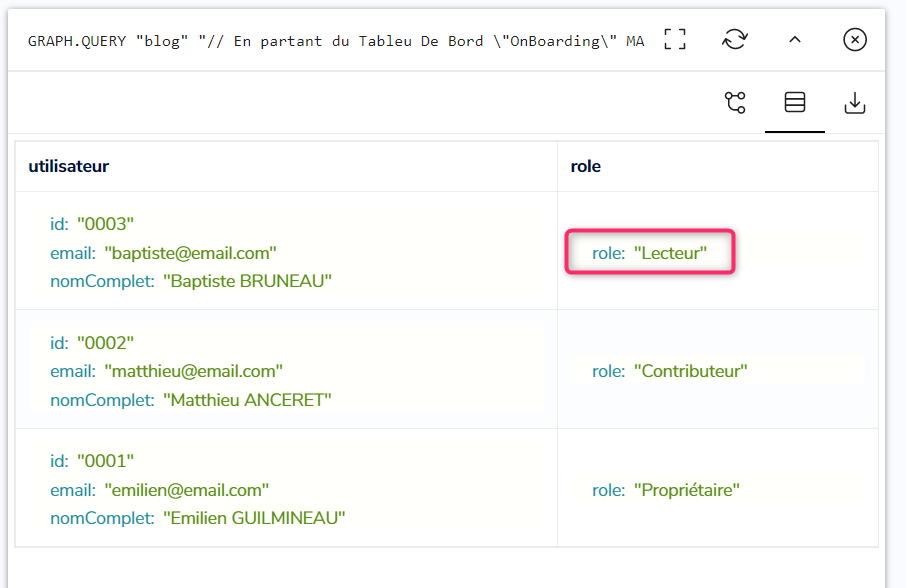
Puis on met à jour le rôle de l’Utilisateur Baptiste afin qu’il passe de Lecteur à Contributeur :
|
|
Le résultat de la requête nous montre que la propriété ‘role’ a été mise à jour :
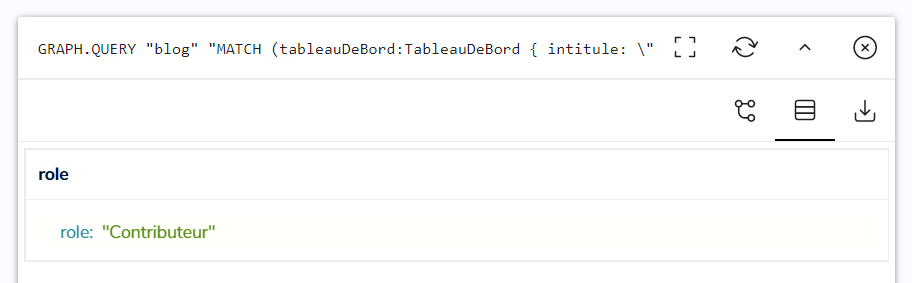
On relance à nouveau la première requête :
|
|
Et Baptiste est alors considéré comme Contributeur :
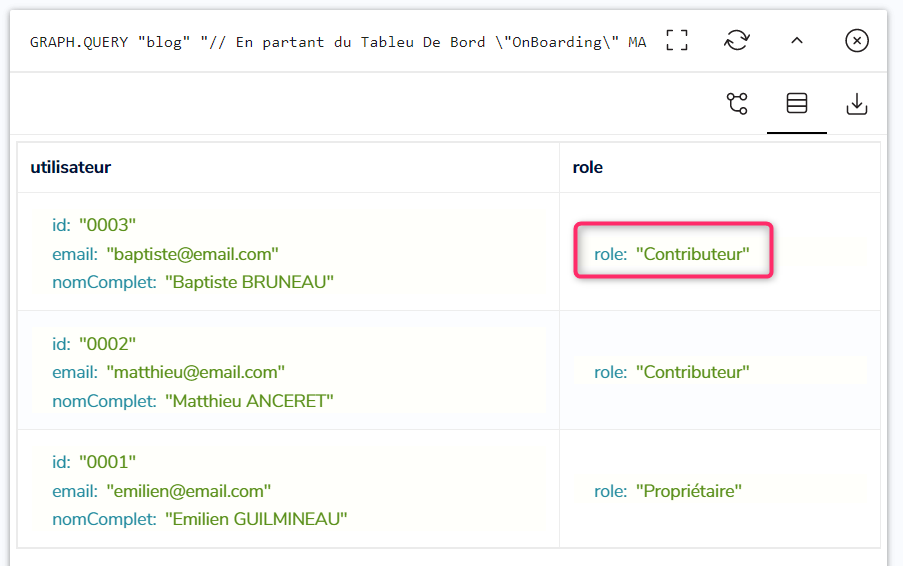
En résumé :
| Utilisateur | Rôle avant | Rôle après |
|---|---|---|
| Emilien GUILMINEAU | Propriétaire | Propriétaire |
| Matthieu ANCERET | Contributeur | Contributeur |
| Baptiste BRUNEAU | Lecteur | Contributeur |
IV. Identifier des questions/cas d’usages supplémentaires
Afin de montrer le déroulement du processus, nous allons partir du principe que le Product Manager de ZeeDash vient de nous soumettre un nouveau besoin.
Problématique
Le PM souhaite que les Propriétaires d’une Entreprise puissent créer des groupes, et y affecter des Utilisateurs, préalablement membres ladite Entreprise.
L’affectation des rôles aux Groupes sera équivalente à celle des Utilisateurs. Et l’affectation d’un rôle à un groupe sera automatiquement propagée à ses Utilisateurs.
Un Groupe est caractérisé par :
- son nom,
- la liste des Utilisateurs qui le composent.
Critère d’acceptation
Le cas d’usage sera considéré comme valide si le modèle de données permet de répondre aux questions suivantes :
- Puis-je valider qu’un utilisateur a le bon rôle pour accéder à un élément, qu’il soit ou non dans un groupe ?
- Puis-je lister tous les utilisateurs, et leurs rôles respectifs, ayant accès à un élément donné, qu’ils soient ou non dans un groupe ?
- Puis-je mettre à jour les droits d’un groupe et voir instantanément la différence de résultat de la requête précédente ?
VI. Affiner le modèle de données
À partir de la description du nouveau besoin, on recommence le travail précédent, en améliorant notre modèle de données.
À la recherche des nœuds
Un nouveau type de nœud fait son apparition :
| Nom commun | Commentaire |
|---|---|
| Groupe | Ensemble nommé d’Utilisateurs, tous membres d’une même Entreprise. |
Nous obtenons donc les types de nœuds suivants :
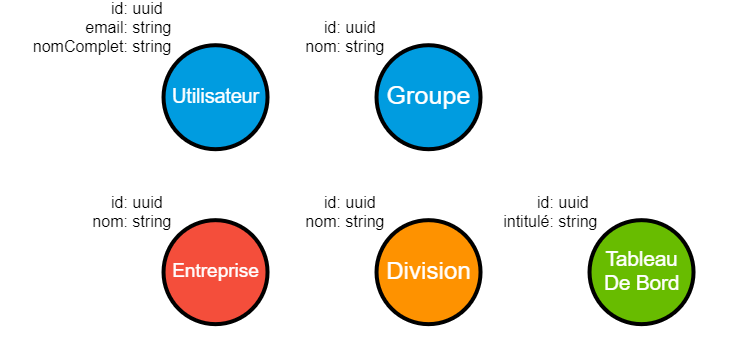
La mise en relation
Ce nouveau nœud est alors relié aux autres éléments à travers les relations suivantes :
| Nœud racine | Relation | Nœud cible | Commentaire |
|---|---|---|---|
| Utilisateur | EST_MEMBRE_DE | GROUPE | Indique que l’utilisateur est membre du Groupe et hérite de ses affectations de rôles. |
| Groupe | A_LE_ROLE | Entreprise ou Division ou Tableau De Bord |
Indique le rôle qu’un groupe a sur un élément, et ses descendants. Le nom du rôle est porté par une propriété de la relation. |
Et après recherche des relations, nous obtenons cette cartographie des relations (les propriétés des nœuds ont été masquées pour plus de lisibilité) :
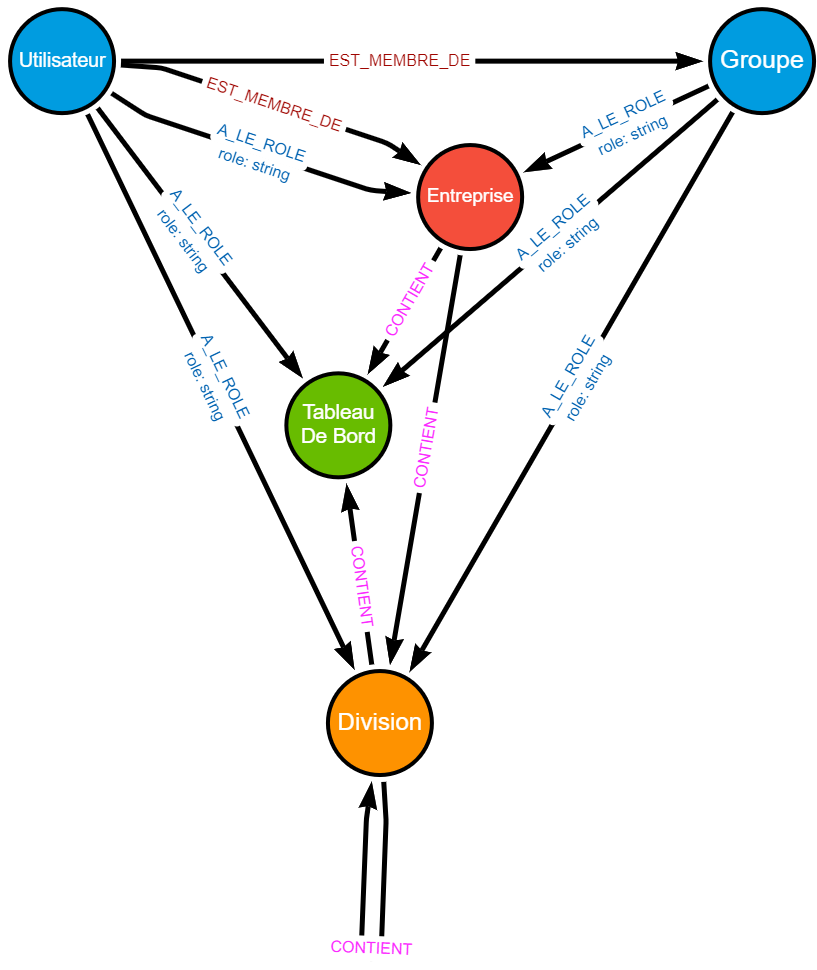
Et voilà ! Notre modèle de données est mis à jour 🎉
VII. Mettre à jour le graphe
Notre modèle de données étant révisé, il faut désormais insérer de nouvelles données dans le graphe, afin de valider qu’il répond aux besoins.
Nous allons ajouter :
- 3 utilisateurs :
- 2 groupes :
- C2S Tours : Groupe contenant des membres de l’équipe de Tours
- C2S Issy : Groupe contenant des membres de l’équipe d’Issy-les-Moulineaux
Pour l’affectation des membres :
- Alexandre et Julien seront membres du groupe ‘C2S Tours’
- Thomas sera membre du groupe ‘C2S Issy’
Pour l’affectation des rôles :
- ‘C2S Tours’ sera ‘Contributeur’ de la Division ‘Dev & IA’
- ‘C2S Issy’ sera ‘Lecteur’ sur le Tableau De Bord ‘OnBoarding’
Cette description doit nous donner un graphe ayant cette forme (seuls les nouveaux éléments y sont montrés pour plus de clarté) :
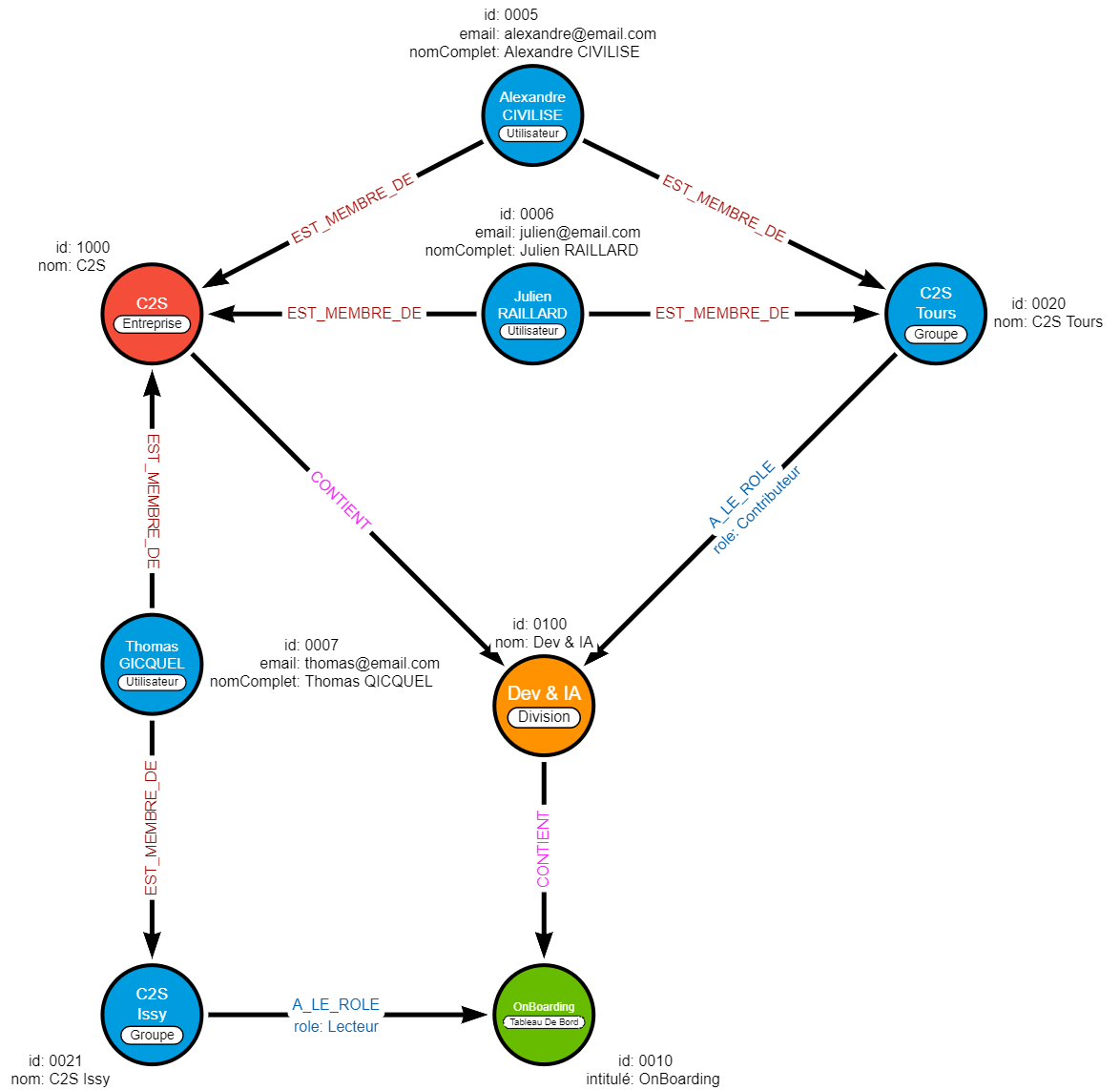
La création des données
Nous pouvons alors rédiger un premier script Cypher permettant d’insérer les données en base de données :
|
|
Note : Nous “étudierons” le langage Cypher dans un article à venir. Votre compréhension de ce script n’est pas primordiale pour la compréhension du reste de l’article.
On obtient alors un graphe prêt à être utilisé, tel que celui-ci :
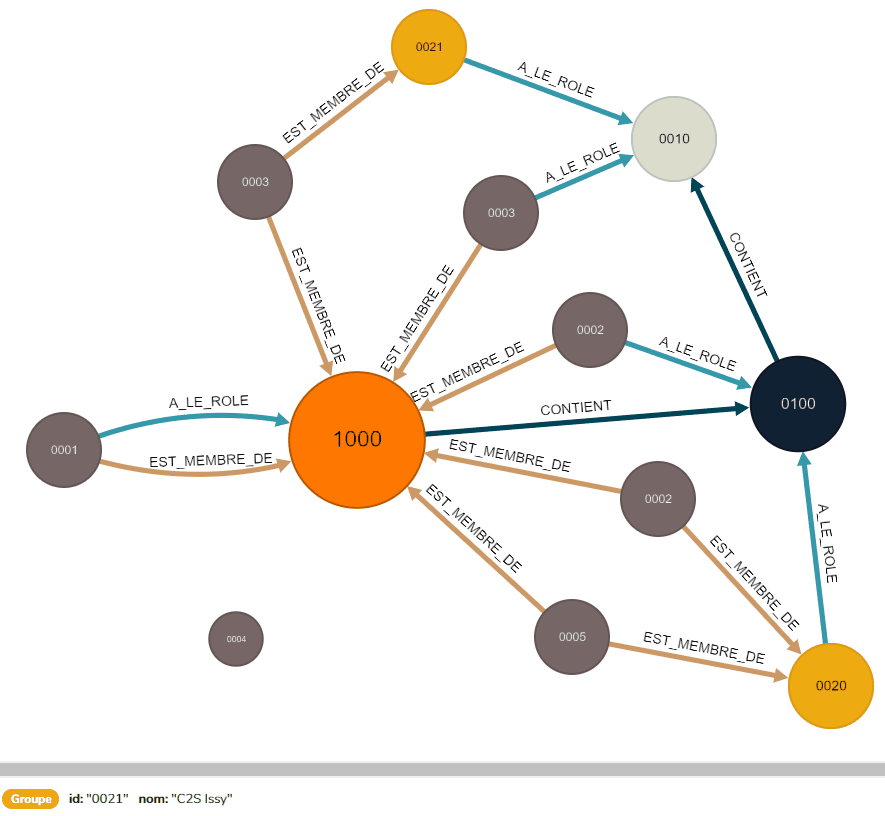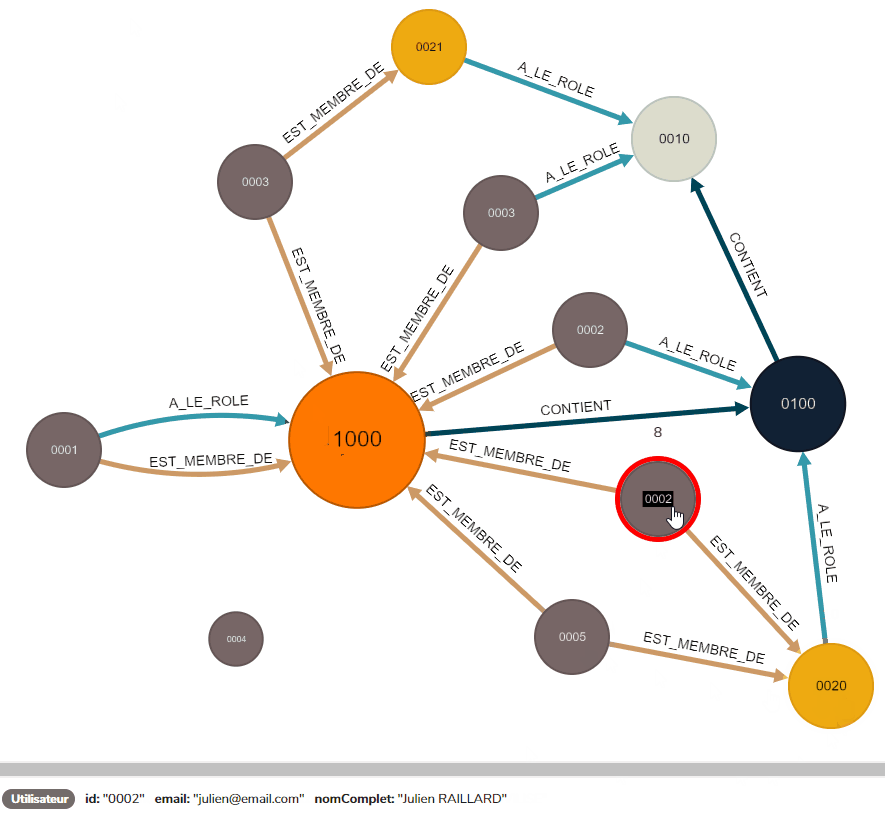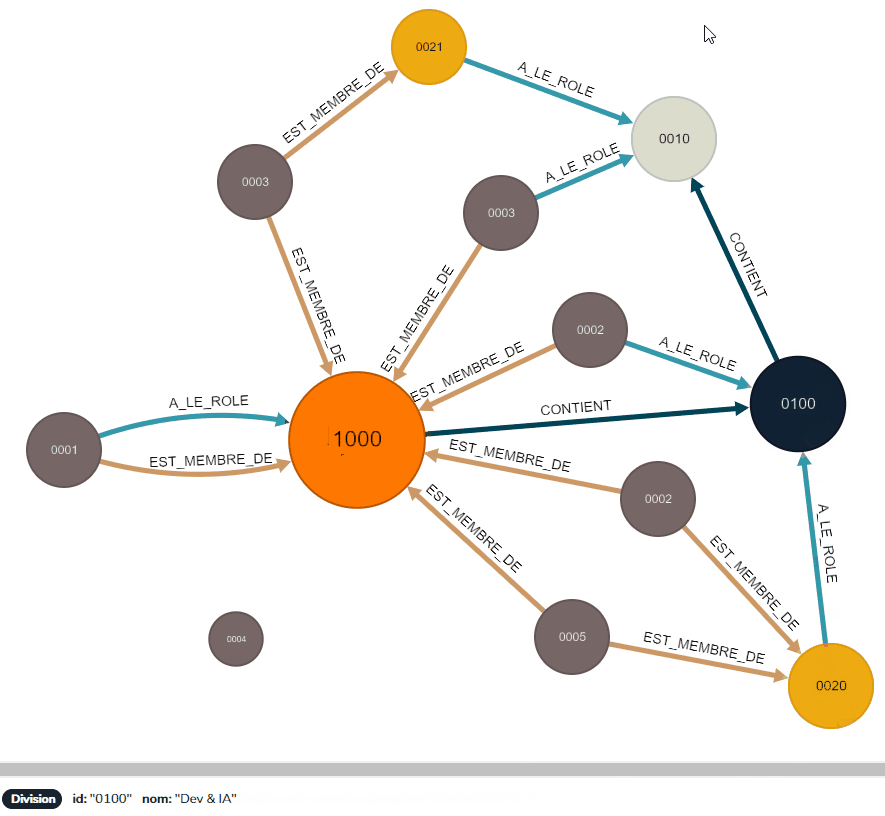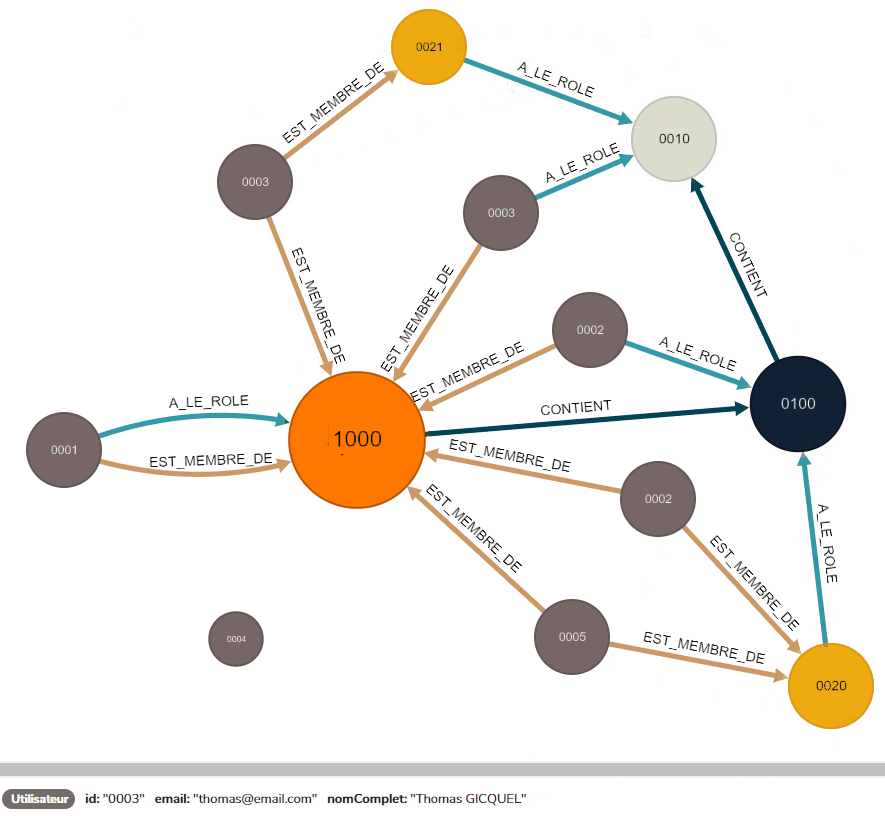
La validation du graphe
Afin de valider son contenu, nous devons réaliser quelques requêtes Cypher. Reprenons les questions des critères d’acceptation.
Rappel : Nous “étudierons” le langage Cypher dans un article à venir. Votre niveau de connaissance de ce langage n’est pas primordial pour la compréhension du reste de l’article.
1. Puis-je valider qu’un utilisateur a le bon rôle pour accéder à un élément, qu’il soit ou non dans un groupe ?
Pour valider que notre graphe permet de répondre à la question de du rôle d’un Utilisateur sur un élément, il nous faut une requête Cypher permettant :
- de sélectionner l’Utilisateur ,
- de sélectionner l’élément ciblé,
- de valider qu’un des chemins du graphe relie l’Utilisateur vers l’élément ciblé, à travers une relation de type
A_LE_ROLE, - de valider que la propriété
rolede la relation a la bonne valorisation.
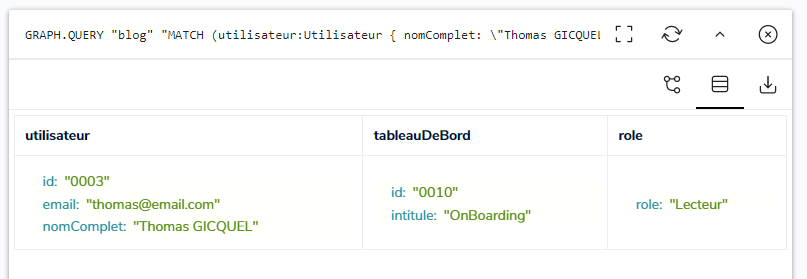
Commençons par utiliser cette requête sur l’Utilisateur Thomas, qui est relié au Tableau De Bord ‘OnBoarding’ de manière indirecte, à travers le groupe ‘C2S Issy’ :
|
|
Le nœud de Thomas et sa relation sont retournés par RedisGraph, l’attribution du rôle est validée :
Réutilisons cette requête, mais en ciblant cette fois l’Utilisateur Baptiste, qui est relié au Tableau De Bord ‘OnBoarding’ de manière directe :
|
|
Le nœud de Baptiste et sa relation sont retournés par RedisGraph, l’attribution du rôle est validée :
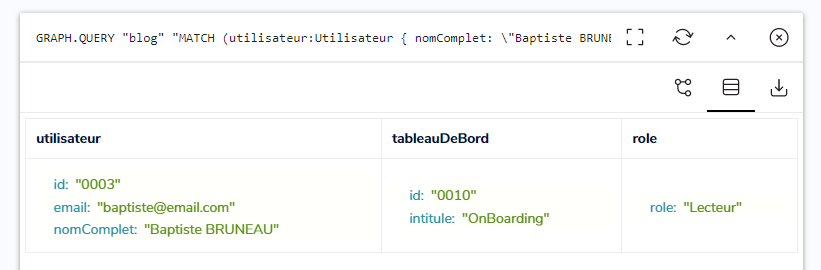
Enfin, pour valider que cette requête est correcte, nous devons l’exécuter sur un cas invalide, où l’utilisateur ne dispose pas du rôle ciblé.
Essayons de trouver cette même relation entre Thomas et la Division ‘Dev & IA’ :
|
|
Aucun nœud n’est retourné par RedisGraph, seulement les statistiques d’exécution de la requête. Ce qui indique que la relation entre les 2 éléments n’existe pas, et donc que le rôle ne lui est pas affecté sur cet élément :
Cette requête Cypher nous permet de confirmer que notre modèle de graphe valide la première question des nouveaux critères d’acceptation.
2. Puis-je lister tous les utilisateurs, et leurs rôles respectifs, ayant accès à un élément donné, qu’ils soient ou non dans un groupe ?
Pour valider que notre graphe permet de lister tous les utilisateurs et leur rôle, de manière directe ou indirecte (à travers les groupes), ayant accès un élément donné, il nous faut un requête Cypher permettant :
- de sélectionner l’Utilisateur
- de sélectionner l’élément source dans la hiérarchie,
- de parcourir la hiérarchie des éléments à travers la relation
CONTIENT, - puis parcourir les affectations de rôles directes et indirectes à travers les relations
A_LE_ROLE.
On obtient alors une requête Cypher correspondant à ceci :
|
|
Les 6 nœuds des utilisateurs sont retournés par RedisGraph, ainsi que les rôles associés :
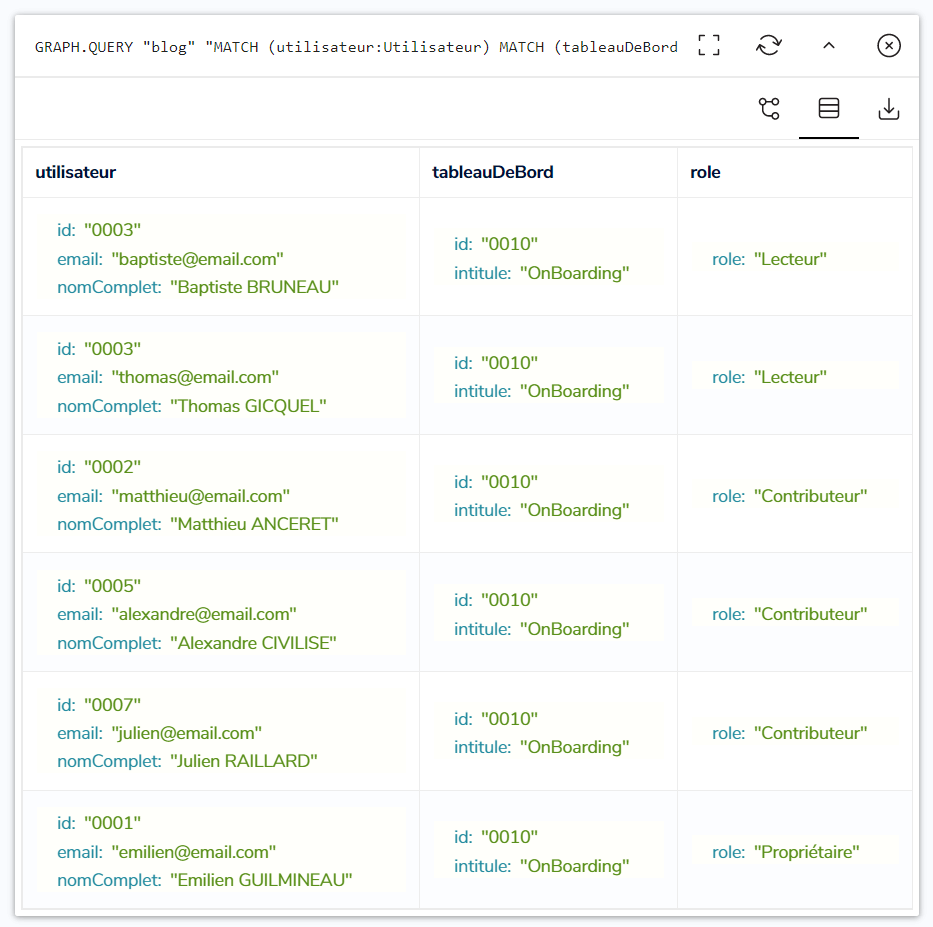
Comme précédemment, en partant de l’élément le plus bas dans la hiérarchie, on récupère tous les utilisateurs ayant un rôle sur les éléments parents, donc la recherche ascendante fonctionne.
Et on constate là aussi Norbert LE VIKING n’est pas présent, donc les utilisateurs n’ayant pas de rôle sur la hiérarchie d’éléments sont bien écartés.
Mais pour valider que cette requête est correcte, nous devons l’exécuter sur un niveau hiérarchique supérieur (ici, la Division ‘Dev & IA’), afin de nous assurer de ne pas retourner des utilisateurs non autorisés.
Recommençons donc, en partant la Division ‘Dev & IA’ :
|
|
Les nœuds de Matthieu et Emilien sont retournés par RedisGraph, comme précédemment, et sont désormais accompagnés de ceux de Julien et Alexandre. Baptiste et Thomas ne sont pas concernés par la Division ‘Dev & IA’, il n’y ont donc pas accès :
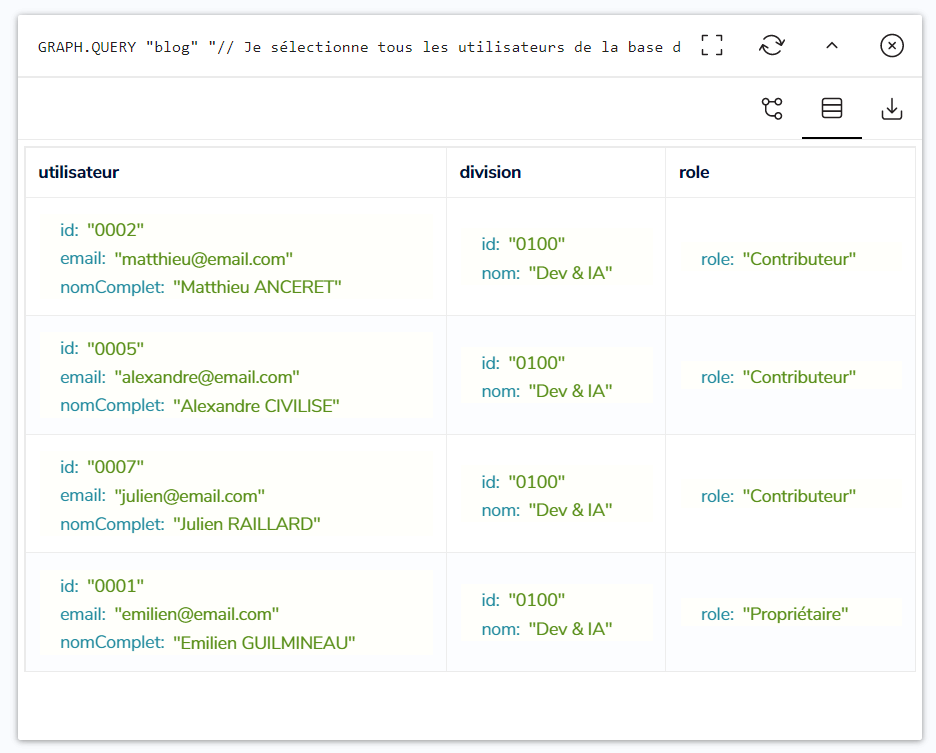
Cette requête Cypher, ciblant d’abord le Tableau De Bord ‘OnBoarding’, puis la Division ‘Dev & IA’, nous a permis de confirmer que notre modèle de graphe valide la deuxième question des nouveaux critères d’acceptation.
3. Puis-je mettre à jour les droits d’un groupe et voir instantanément la différence de résultat de la requête précédente ?
Pour valider la prise en compte immédiate des modifications de rôles, 1 trio de requête Cypher suffit :
- Je recherche les rôles d’un Groupe sur un élément, un Tableau De Bord par exemple
- J’ajoute, modifie ou supprime un rôle du Groupe sur l’élément
- Je recherche à nouveau les rôles du Groupe sur le Tableau De Bord, et je compare les résultats
On repart donc de la requête du sous-chapitre précédent :
|
|
Qui nous retourne les 6 nœuds des utilisateurs, ainsi que les rôles associés :
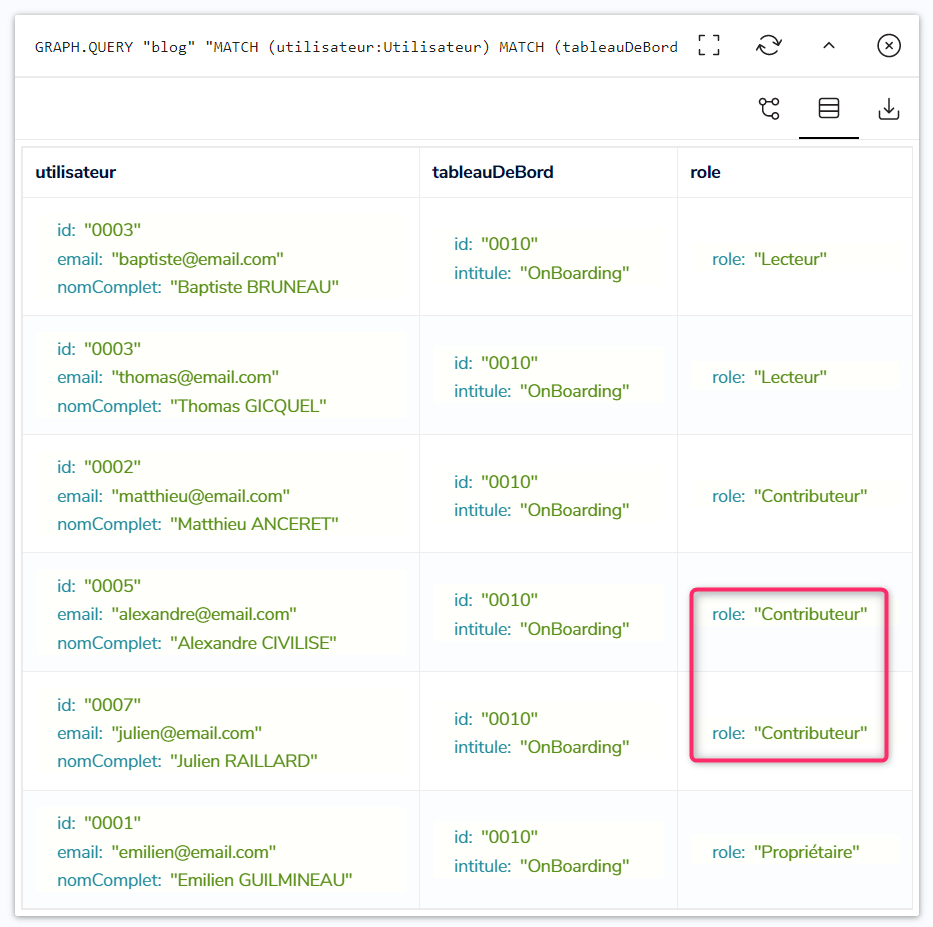
Puis on fait passer le Groupe ‘C2S Tours’ de Contributeur à Lecteur, sur la Division ‘Dev & IA’ :
|
|
Le résultat de la requête nous montre que la propriété ‘role’ a été mise à jour :
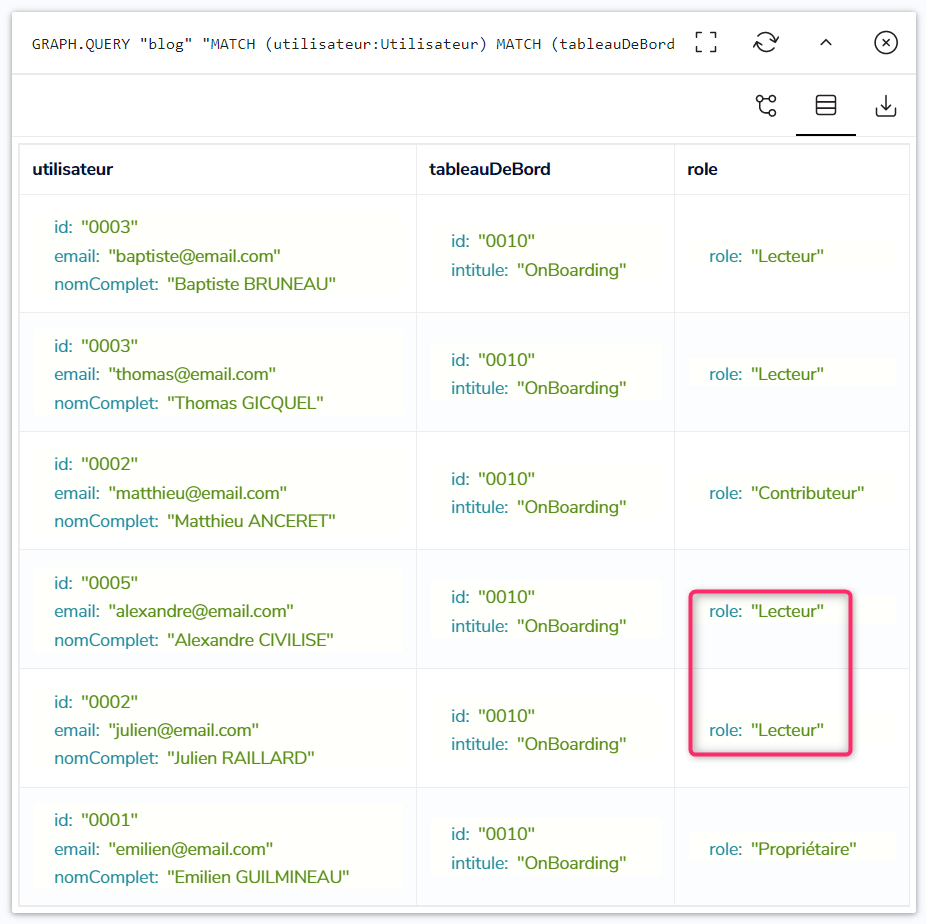
On relance à nouveau la première requête :
|
|
Alexandre et Julien, qui sont membres du Groupe ‘C2S Tours’, sont alors considérés comme Lecteur :
En résumé :
| Utilisateur | Rôle avant | Rôle après |
|---|---|---|
| Emilien GUILMINEAU | Propriétaire | Propriétaire |
| Matthieu ANCERET | Contributeur | Contributeur |
| Alexandre CIVILISE | Contributeur | Lecteur |
| Matthieu ANCERET | Contributeur | Lecteur |
| Baptiste BRUNEAU | Lecteur | Lecteur |
| Thomas GICQUEL | Lecteur | Lecteur |
Conclusion
Tout d’abord, BRAVO !
Cet article était long, mais nécessaire, et vous en êtes arrivé au bout, après plus de 30 minutes de lecture 💪
Au fur et à mesure de cet article, vous aurez sûrement constaté que le processus présenté n’est pas compliqué, il demande juste à être suivi.
Une dernière clarification à apporter concerne les différentes étapes qui le composent. Elles sont à effectuer par les différents profils d’intervenants selon ce schéma :
| # | Étapes | Stakeholder | Développeur |
|---|---|---|---|
| 1 | Comprendre le domaine métier et ses cas d’usages | ✅ | ✅ |
| 2 | Concevoir le modèle de données initial | ✅ | |
| 3 | Créer le graphe avec des données | ✅ | |
| 4 | Identifier des questions/cas d’usages supplémentaires | ✅ | ✅ |
| 5 | Affiner le modèle de données | ✅ | |
| 6 | Mettre à jour le graphe | ✅ |
Répétez les étapes 4 à 6 afin d’améliorer en continu le modèle de données
Et s’il y a bien une chose à retenir de ce processus, c’est que la modélisation des données d’un graphe n’est pas une Activité Ponctuelle, mais bien un processus continu.
En effet, les systèmes changent, évoluent, et avec le rythme effréné des développements applicatifs d’aujourd’hui, il y a fort à parier que les modèles de données de vos applications évolueront drastiquement avec le temps, et parfois même en plein milieu des développements.
Dès lors, autant choisir une technologie qui permet de faire évoluer rapidement la structure des données qui la compose, à travers un modèle de données simple et proche des besoins métiers, plutôt que de choisir des bases de données relationnelles aux schémas de données plus rigides, et parfois compliqué à modéliser.
Merci pour votre attention et votre lecture.
Rendez-vous dans l’article suivant, où nous aborderons le langage CypherQL.