
Graph DB : Comment identifier les usages ?
Cet article fait partie d’une série sur les bases de données orientées graphe, dont vous retrouverez l’intégralité des articles ici : Les bases de données orientées graphe
Comment identifier les usages ?
Si grâce à l’article précédent vous avez désormais une vision générale de ce que sont les Graph DB par rapport aux autres types de bases de données, vous devez probablement vous demander :
Comment détecter qu’un besoin/contexte métier peut nécessiter l’usage d’une Graph DB ?
Et bien bonne nouvelle, il existe 4 questions à se poser pour savoir si l’on a besoin de recourir à une Graph DB.
Les 4 questions à se poser
Sachez qu’avant de vous poser ces questions, vous devez à minima avoir compris le besoin métier qui vous est exprimé.
Sans cela, les choix que vous prendrez pourront s’avérer infructueux, au point de choisir une Graph DB là où un Document Store serait plus pertinent, ou de rester sur une base de données relationnelle là où une Graph DB vous apporterait plus de flexibilités et de performances.
Note : cette situation n’est pas propre aux Graph DB.
En tant qu’ingénieurs logiciel, nous nous devons d’avoir compris les besoins métiers, au moins dans les grandes lignes, avant de prendre des décisions structurantes.
I. L’importance des relations
La première question que l’on doit se poser est :
Est-ce que le besoin nécessite de comprendre les relations entre les entités ?
En d’autres termes, est-ce que les problèmes, que je vais devoir résoudre, vont nécessiter de s’interroger sur les intentions que décrivent les relations de mon modèle ?
Bien évidemment, pour que les intentions portées par vos relations soient pertinentes, il vous faudra une modélisation allant dans ce sens.
SPOILER : c’est le sujet du prochain article 😁
Mais le but de cette question est de savoir si je vais pouvoir exploiter les relations de mon modèle, grâce à l’intention qu’elles véhiculent, afin d’obtenir un résultat me permettant de résoudre mon problème.
| Cas d’usages résultants | Exemple |
|---|---|
Moteur de recommandationsRecommandations |
Afficher une liste d’articles équivalents sur une page produit. |
Déduction de la meilleure action suivanteNext Best Actions |
Proposer les prochains articles à ajouter au panier, directement après avoir cliqué sur le bouton “Ajouter au panier”. |
Détection de fraudesFraud detection |
Déterminer si des tiers (physiques et moraux) qui se “connaissent” sont sujets à une tentative de fraudes : Fraude bancaire, fraude à l’assurance … |
Résolution d’identitéIdentity resolution |
Déterminer si en fonction de leurs données personnelles, 2 personnes enregistrées dans un système sont en fait une seule et même personne |
Généalogie/Origine des donnéesData Lineage |
Déterminer l’origine d’une donnée dans un système : La donnée/l’information X provient du sous-système Y, qui collecte les données à partir de l’outil Z |
II. De moi vers moi
La deuxième question que l’on doit se poser est :
Est-ce que le besoin implique beaucoup d’autoréférences à un même type d’entité ?
Tout d’abord, commençons par clarifier ce que l’on entend par “autoréférence”.
Prenons l’exemple de l’organisation hiérarchique des filiales de la société Unlimited Corp.:
flowchart LR Root(Unlimited Corp.) ---> FR(Unlimited France) FR(Unlimited France) ---> FRN(Unlimited France Nord) FRN(Unlimited France Nord) ---> Amiens(Unlimited Amiens) FRN(Unlimited France Nord) ---> Lille(Unlimited Lille) FRN(Unlimited France Nord) ---> Paris(Unlimited Paris) FRN(Unlimited France Nord) ---> Rouen(Unlimited Rouen) FR(Unlimited France) ---> FRO(Unlimited France Ouest) FRO(Unlimited France Ouest) ---> LeMans(Unlimited Le Mans) FRO(Unlimited France Ouest) ---> Nantes(Unlimited Nantes) FRO(Unlimited France Ouest) ---> Tours(Unlimited Tours) FRO(Unlimited France Ouest) ---> Rennes(Unlimited Rennes) Root(Unlimited Corp.) ---> ES(Unlimited España) ES(Unlimited España) ---> ESN(Unlimited España Norte) ES(Unlimited España) ---> ESO(Unlimited España Oeste) style Root fill:green style FR fill:blue style FRN fill:darkblue style FRO fill:dodgerblue style ES fill:red style ESN fill:darkred style ESO fill:indianred
Dans cet exemple, chaque filiale possède un ensemble de filiales filles, permettant ainsi de construire un arbre hiérarchique pour l’ensemble de la société et des ses filiales.
Avec une base de données relationnelles, la profondeur de la hiérarchie étant inconnue et probablement variable d’un pays à l’autre, la modélisation de cet arbre se rapprocherait probablement d’une table SQL comme celle-ci :
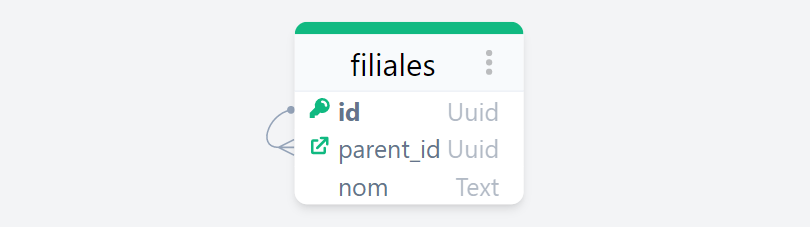
La colonne parent_id de la table filiales référence la colonne id de cette même table SQL. On dit donc que la table s’autoréférence.
Or, cette modélisation pose plusieurs problèmes :
- Premièrement, le langage SQL n’est pas adapté au parcours de graphe, vous serez donc probablement contraint d’utiliser des CTE pour arriver à vos fins.
- Deuxièmement, cet autoréférencement aura un coup à la lecture sur le parcours des index et de la table, pour le moteur de base de données.
Mais alors pourquoi les Graph DB sont-elles mieux adaptées à ce cas d’usage ?
Étant donné que chaque nœud d’une Graph DB contient à la fois ses données et ses relations, le coût de l’opération relative au parcours des index et à la lecture de la table SQL n’a plus lieu d’être. Il est quasiment neutre par rapport à une base de données relationnelles.
Enfin, les langages de requêtes utilisés pour ces bases de données, Cypher et Gremlin, ont été conçus dans l’optique de résoudre des parcours de graphes.
NDLR : Nous aborderons plus en détail ces langages dans un article à venir.
| Cas d’usages résultants | Exemple |
|---|---|
Hiérarchies organisationnellesOrganisational hierarchies |
Gérer les niveaux hiérarchiques d’une entreprise (comme l’exemple). |
Cercle d’amisFriends of Friends |
Analyser les relations entre les utilisateurs d’un réseau social, tels que Twitter ou Facebook. |
Influenceurs sociauxSocial influencers |
Analyser les interactions entre les utilisateurs d’un réseau social, tels que Twitter ou Facebook. |
III. La profondeur des abysses
La troisième question que l’on doit se poser est :
Est-ce que le besoin consiste à explorer des relations entre entités de profondeur variable ou inconnue ?
Pour bien comprendre la notion de profondeur, revenons sur le diagramme organisationnel de Unlimited Corp. présenté précédemment.
Ce diagramme contenait :
- L’élément racine : La maison mère de Unlimited Corp.
- 1er niveau : Une succursale par pays
- 2ème niveau : Une succursale suivant un découpage par point cardinal du pays (Nord, Sud, Est et Ouest)
- 3ème niveau : Une filiale par ville où est implantée Unlimited Corp.
Dans le diagramme précédent, si la France allait jusqu’au 3ème niveau avec des villes telles que Paris, Nantes ou Le Mans, l’Espagne, elle, n’allait pas au-delà du 2ème niveau, avec un découpage par point cardinal.
On va alors considérer que la France a une profondeur de 3 et l’Espagne une profondeur de 2.
En effet, en partant de l’élément racine, il faudra suivre 3 relations pour atteindre la fin du diagramme pour la France, et suivre 2 relations pour l’Espagne.
Un exemple plus concret, présent dans le monde de l’informatique, est la Nomenclature logicielle (aka SBOM).
Cette nomenclature permet aux entreprises de connaître et surveiller les dépendances logicielles présentes dans leurs infrastructures. Avec une nomenclature logicielle correctement maintenue, une entreprise peut réagir rapidement aux risques de sécurité, de licence, ou face aux risques opérationnels.
Par exemple, lors de la découverte de l’attaque Log4Shell, les entreprises disposant d’une Nomenclature logicielle ont pu rapidement déterminer quels applicatifs étaient concernés par l’attaque.
Sur le graphe d’exemple ci-dessous, on voit le suivi d’une API et de ses 3 versions (1.0.0, 1.1.0 et 2.0.0), ainsi que le suivi de déploiement des firmwares de routeurs. Chacun de ses éléments est relié à la version de Log4J qu’il utilise. :
- En rouge : la version de Log4J qui pose problème
- En orange : Les éléments qui dépendent de la version défectueuse
- En vert : La version corrigée et les éléments qui en dépendent
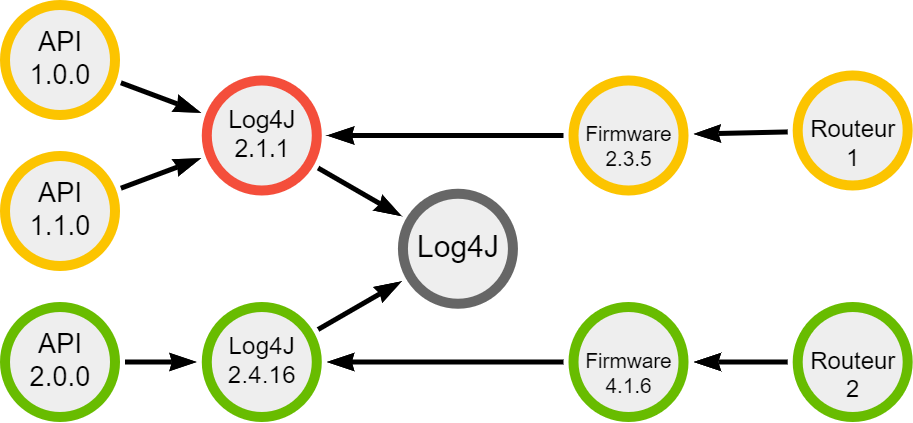
En partant de la version défectueuse de Log4J, on ne sait pas initialement combien de relations vont devoir être traversées pour arriver à une fin de graphe (seulement 1 pour les API, et 2 pour les routeurs).
Dans notre cas, la profondeur est variable, mais avec une nomenclature plus réaliste, cette profondeur dépendrait de la structuration choisie par l’entreprise, et deviendrait donc inconnue.
| Cas d’usages résultants | Exemple |
|---|---|
Visibilité de la chaîne d’approvisionnementSupply chain visibility |
Déterminer quels sont les fournisseurs à risque, et définir les flux à adopter en cas de problème d’approvisionnement. |
NomenclatureBill of Materials |
Répertorier la liste de tous les éléments présents sur un système (infrastructure IT, véhicules, …) afin de mieux gérer les cas de défection. |
La gestion du réseauNetwork management |
Analyser les pannes, les performances et la capacité des réseaux (informatique, eau, électricité), en vue de maintenir une qualité de service constante. |
IV. Tous les chemins mènent à Rome
La dernière question que l’on doit se poser est :
Est-ce que le besoin consiste à découvrir un grand nombre d’itinéraires ou de chemins différents ?
Si vous êtes dans un mode exploratoire, que vous connaissez votre point de départ et votre point d’arrivée, mais que vous cherchez le chemin qui convient le mieux à votre besoin (en temps, en distance, en coût, par période, par durée …), alors une Graph DB sera parfaite pour votre besoin.
Un exemple assez simple pour visualiser la notion d’itinéraire est celui de la grille de métro de Paris.
Pour aller de la Gare Montparnasse à la place de l’Opéra, vous pouvez :
- soit prendre le bus 95
- soit prendre la ligne 13 depuis la station Pernety, jusqu’à la station Saint-Lazare, et marcher sur la fin
- soit prendre la ligne 13 depuis la station Gaîté, jusqu’à la station Invalides, puis la ligne 8 toujours depuis la station Invalides, jusqu’à la station Opéra
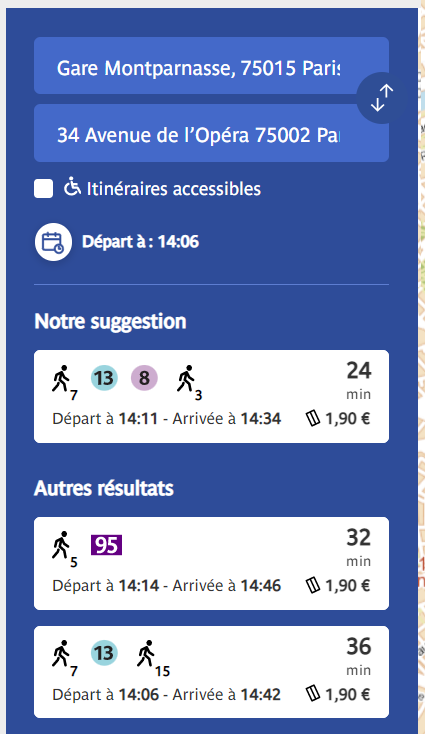
Chacun des trajets ci-dessus vous permet de répondre à la question “Quels sont les itinéraires qui me permettent d’aller de la Gare Montparnasse à la place de l’Opéra ?”.
Et les Graph DB sont d’excellents outils pour répondre à ces questions.
| Cas d’usages résultants | Exemple |
|---|---|
Logistique et routageLogistics and routing |
Déterminer le meilleur trajet à suivre pour récupérer ou déposer des colis. |
Gestion des infrastructuresInfrastructure management |
Déterminer dans quelle région AWS/Azure/GCP héberger un système d’information pour optimiser sa facture finale. |
Suivi des dépendancesDependency tracking |
Déterminer quelle dépendance d’une organisation (système informatique, sous-traitant, matières premières …) peut la ralentir, voir la faire tomber, en cas de défaillance ou de disparition. |
En conclusion
Bien que tous les cas précédemment cités peuvent théoriquement être résolus avec d’autres types de bases de données, seules les Graph DB vous assurent un niveau décent de performance et un modèle de travail adapté pour les résoudre. Je ne peux donc que vous conseiller de vous poser ces questions !
Et si vous répondez Oui à l’une d’entre-elles, alors il faudra vous questionner sur la technologie de base de données que vous souhaitez utiliser sur votre projet, ou peut-être remettre en cause celle que vous utilisez déjà.
Dans l’article suivant, nous traiterons de la méthode à suivre pour modéliser ses données dans une Graph DB.