
Graph DB : Qu'est-ce que c'est ?
Cet article fait partie d’une série sur les bases de données orientées graphe, dont vous retrouverez l’intégralité des articles ici : Les bases de données orientées graphe
Bienvenue !
Si vous vous demandez ce que sont les bases de données orientées graphe, ou Graph DB, et que vous cherchez à comprendre comment elles fonctionnent, alors soyez les bienvenues !
Je vais tenter de vous faire découvrir une famille de base de données dont le paradigme n’est pas juste de stocker de grandes quantités de données de manière distribuée, mais de réimaginer notre rapport à la donnée en se focalisant sur la notion de relation.
C’est parti !
Qu’est-ce qu’un graphe ?
Pour bien comprendre ce que sont les Graph DB, il faut d’abord comprendre ce qu’est un graphe.
BONNE NOUVELLE : Pas besoin d’être ultra calé en math et de connaître par cœur la théorie des graphes !
À vrai dire, c’est même plus abordable que la logique associée aux bases de données relationnelles.
Des ronds, des flèches …
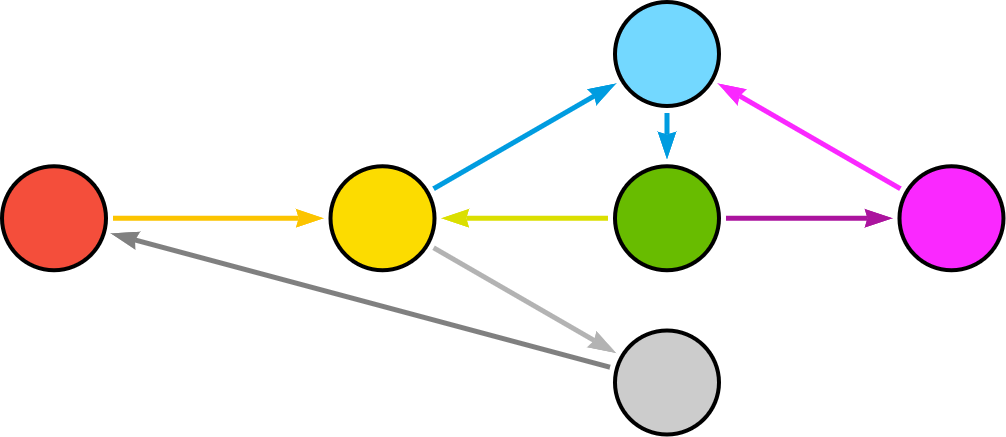
À l’image de la bannière en haut de cet article, tous les graphes sont composés de 2 éléments “de base” :
- Des nœuds : représentés par des ronds, ils symbolisent une
entité(un lieu, un objet, une personne, un animal …).
On les retrouve sous le nom deverticedans la littérature anglo-saxonne. - Des relations : représentées par des flèches, elles symbolisent l’association entre 2 nœuds, ainsi que l’orientation de la relation (dans quel sens a-t-elle lieu).
On les retrouve sous le nom deedgedans la littérature anglo-saxonne.
Ces 2 éléments suffisent à décrire visuellement un graphe :

… et un peu de contexte
Cependant, travailler uniquement avec des ronds et des flèches n’est pas suffisant pour véhiculer une idée.
C’est pourquoi on utilise 2 autres éléments, dits “contextuels”, pour décrire le modèle de données d’un graphe :
- Des propriétés : Aucune forme géographique n’est associée à cet élément. Les propriétés ne sont représentées que par du texte, à travers une paire clé/valeur.
On les retrouve sous le nom depropertiesdans la littérature anglo-saxonne. - Des étiquettes : Aucune forme géographique n’est associée à cet élément. Elles ne sont représentées que par du texte simple sur les nœuds.
On les retrouve sous le nom decaptionoulabeldans la littérature anglo-saxonne.
Les propriétés peuvent être apposées aussi bien sur des nœuds que sur des relations, et plusieurs propriétés peuvent être posées simultanément sur un même nœud ou une même relation. A contrario, les étiquettes ne sont posées que sur des nœuds, et pas sur des relations.
Voici un exemple de graphe représentant ma situation professionnelle au moment de la rédaction de cet article :
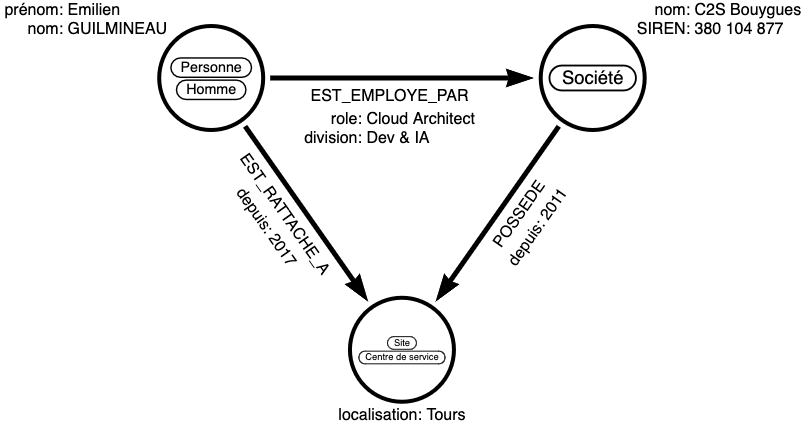
On y distingue 3 nœuds :
- Moi : Avec les étiquettes
PersonneetHomme, et les propriétésnometprénomvalorisées. - Une société : Avec l’étiquette
Sociétéet les propriétésnometSIRENvalorisées. - Un site : Avec les étiquettes
SiteetCentre de service, et la propriétélocalisationvalorisée.
Ces 3 nœuds sont reliés par des relations :
EST_EMPLOYE_PAR: Détermine qui est mon employeur, ainsi que leroleet ladivisionà laquelle je suis affecté à travers des propriétés du même nomEST_RATTACHE_A: Indique l’emplacement auquel je suis rattache, ainsi que l’année de début de mon rattachement à ce site à travers la propriétédepuisPOSSEDE: Indique que la société possède un emplacement physique, ainsi que l’année d’ouverture/possession de l’emplacement à travers la propriétédepuis
Note : Dans cet exemple, les flèches sont unidirectionnelles et le graphe semble partir de moi pour aller vers le site de Tours. Rien n’interdit 2 nœuds d’avoir une relation dans un sens, et une autre dans le sens inverse.
Et c’est tout ?
Et oui, c’est tout !
Pas du jargon technique comme on peut le retrouver avec les bases de données relationnelles, tel que les jointures, les clés primaires et autres index.
Un graphe est composé d’entités, et de relations entre les entités, sur lesquels on vient poser des étiquettes et/ou des propriétés.
Pourquoi s’intéresser aux bases de données orientées graphe ?
Historiquement, la plupart des “applications d’entreprises” étaient conçues autour de bases de données relationnelles (aussi appelées SGBDR dans la suite de l’article), et cela pour d’excellentes raisons environnementales :
- la disponibilité et la maturité des produits disponibles,
- le vivier de personnes compétentes sur le marché de l’emploi,
- les faibles problématiques de volumétrie et variété d’informations,
- …
Mais au cours des dernières décennies, l’avènement d’internet et l’augmentation du nombre d’informations numériques échangées ont changé la donne. À tel point que les bases de données relationnelles se sont parfois retrouvées à être utilisées dans des situations qu’elles ne pouvaient pas gérer efficacement.
C’est alors que le mouvement NoSQL (acronyme de Not only SQL) a émergé, et que de nouveaux paradigmes autour de la gestion de la donnée sont apparus. Parmi eux, le modèle de données orienté graphe.
Si le paradigme des graphes nous intéresse aujourd’hui, c’est parce qu’il va bien au-delà des bases de données et du développement d’application. Il nous invite à repenser notre manière de voir la donnée en se concentrant sur les interconnexions qui existent entre les données. Il nous invite à représenter “le monde réel” non plus sous un ensemble de données isolées, mais de données interconnectées.
Et les Graph DB répondent parfaitement à ce paradigme.
Parmi les points forts qu’elles possèdent, on peut retenir :
- Les performances
- Le volume de données que vous traitez et stockez actuellement va continuer à augmenter au fur et à mesure du temps. Et si votre “Big Data” augmente de manière linéaire, les interconnexions entre les données que vous stockez vont, elles, augmenter de manière exponentielle.
- Avec une approche traditionnelle, les requêtes relationnelles atteignent rapidement leurs limites au fur et à mesure que le nombre et la profondeur des relations augmentent. A contrario, les performances d’une base de données orientée graphe restent constantes malgré une volumétrie croissante de données et de relations.
- La flexibilité du modèle
- Contrairement à une base de données relationnelle, le modèle de données d’un graphe n’est pas fortement structuré. Cela permet aux développeurs de créer le modèle de données de manière incrémentale, en suivant les besoins métiers au fur et à mesure qu’ils arrivent. Plus besoin de passer un temps considérable, en amont des développements, à définir un modèle de données qui sera généralement modifié, voir reconstruit, avec l’évolution des besoins métiers.
- Si ce point n’est pas propre aux bases de données orientées graphe, il a l’avantage de redonner la main aux équipes techniques, plutôt que de les contraindre à représenter leurs données à travers un modèle tabulaire.
Quel intérêt par rapport aux autres systèmes de base de données ?
S’il est indéniable que les bases de données relationnelles sont pertinentes (si ce n’était pas le cas, elles ne seraient pas autant utilisées ^^), l’arrivée du mouvement NoSQL a quelque peu changé la donne pour ce modèle de stockage des données qui régnait en maître depuis des décennies.
Je ne dis pas que le modèle SGBDR est mauvais (ce n’est absolument pas le cas), mais lorsqu’il est utilisé comme modèle ‘fourre-tout’ (one-size-fits-all en anglais) … eh bien … il faut s’attendre à rencontrer quelques inadéquations, quelques décalages entre le plan initial et le résultat final …
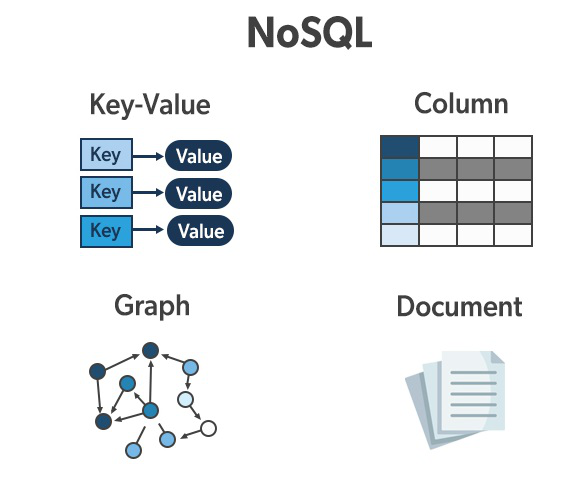
Pour dépasser certaines des limitations du modèle SGBDR, 4 grands types de bases de données sont apparus :
Key-Value: LeKV Storeest le type de bases de données NoSQL le plus simple qui soit.
Chaque donnée dans la base est stockée sous la forme d’une paire clé/valeur, composée d’un nom unique (la “clé”) et de sa valeur associée.
Les principaux avantages desKV Storeson l’évolutivité, la rapidité et la flexibilité.
En effet, ils gèrent bien la charge et sont bons pour traiter un flux constant d’opérations de lecture/écriture. Par ailleurs, ils utilisent des commandes opérationnelles simples telles queGET,PUT,DELETE… et la combinaison de ces deux éléments les rend très flexibles, notamment pour gérer divers besoins tels que, la gestion des sessions utilisateurs à grande échelle, le cache de données applicatives …Column-Oriented: Contrairement aux bases de données relationnelles, qui stockent les données en lignes et lisent les données ligne par ligne, unColumn Storeest organisé en un ensemble de colonnes.
Cela signifie que lorsque vous souhaitez exécuter des analyses sur un petit nombre de colonnes, vous pouvez lire les données de ces colonnes directement sans consommer de mémoire avec les données indésirables.
Les cas d’utilisation de ce type de base de données sont généralement orientés vers de l’analytics.Document-Oriented: Comme leur nom l’indique, lesDocument Storestockent des documents (-‸ლ)
Ces documents peuvent être au format JSON, BSON ou encore XML.
Ils doivent leur popularité auprès des développeurs au faible couplage du moteur de base de données avec la structure des documents stockés. Les développeurs peuvent ainsi y insérer des documents avec des structures variées, et s’attendre à d’excellentes performances d’écriture puisque la structure des données n’est plus un facteur à prendre en compte par le moteur de base de données.
Les cas d’utilisation incluent les plateformes de commerce en ligne, les plateformes de trading, ….Graph-Oriented: Enfin, les Graph DB se concentrent sur la relation entre les données.
Chaque nœud est stocké avec ses propriétés/étiquettes ET ses relations ! Là où dans les bases de données relationnelles les liens sont implicites, utilisant des données dédiées pour exprimer les relations.
Ce modèle de stockage offre donc un coût théorique deO(1)(une seule opération) pour accéder aux données liées, et garde le même coût quelque soit la quantité de données dans le graphe.
Les Graph DB sont optimisées pour capturer et rechercher les connexions entre les données, en maîtrisant la surcharge associée à la jointure des tables dans SQL.
Les cas d’utilisation incluent la détection des fraudes, les réseaux sociaux et les graphes de connaissances …
En définitive, chacun de ses types de base de données NoSQL a permis de dépasser une des contraintes imposées par les systèmes de bases de données relationnelles :
- La performance pour les bases de données
Key-Value, grâce à une structure de données simples - L’efficience pour les bases de données
Column-Oriented, grâce à une maîtrise de la consommation de ressource lors des lectures - La versatilité pour les bases de données
Document-Oriented, grâce à un couplage faible entre la structure des données stockées et le moteur de base de données - La découvrabilité pour les bases de données
Graph-Oriented, grâce à l’intégration des relations comme élément fondamental de la donnée
Et ensuite ?
Et bien comme le disait Frederic P. Brooks, dans une publication parue en 1986 :
There is […] no silver bullet
No Silver Bullet — Essence and Accident in Software Engineering
En réalité, chacun des types de bases de données NoSQL a réussi avec brio à dépasser une des contraintes imposées par les SGBDR, mais pas toutes les contraintes simultanément.
Car (je le répète) le modèle SGBDR est pertinent, qu’il s’agisse de son langage de requête (le SQL), ses contraintes de modélisation (clé unique, non nullabilité …), sa représentation tabulaire facile à comprendre …
Cependant, là où les Graph DB ont su tirer leur épingle du jeu, c’est sur l’importance qu’elles accordent aux relations entre les données.
Car de ces relations peuvent naître des analyses comportementales (détection de fraudes), relationnelles (réseaux sociaux), … que les autres types de base de données ne sauraient pas gérer aussi efficacement.